
Code
Cabin Escape
The Idea
I worked together with a few fine folks from my team on a very fun hackathon project, and I want to tell you about it.
The team was myself (@codefoster), Jennifer Marsman (@jennifermarsman), Hao Luo (@howlowck), Kwadwo Nyarko (@kjnyarko), and Doris Chen (@doristchen).
Here’s our team…

The hackathon was themed on some relatively new products - namely Cognitive Services and the Bot Framework. Additionally, some members of the team were looking for some opportunity to fine tune their Azure Functions skills, so we went looking for an idea that included them all.
I’ve been mulling around the idea of using some of these technologies to implement an escape room, which as you may know are very popular nowadays. If you haven’t played an escape room, perhaps you want to find one nearby and give it a try. An escape room is essentially a physical room that you and a few friends enter and are tasked with exiting in a set amount of time.
Exiting, however, is a puzzle.
Our escape room project is called Cabin Escape and the setting is an airplane cabin.
Game Play
Players start the game standing in a dark room with a loud, annoying siren and a flashing light. The setting makes it obvious that the plane has just crash landed and the players’ job is to get out.
Players look around in haste, motivated by the siren, and discover a computer terminal. The terminal has some basic information on the screen that introduces itself as CAI (pronounced like kite without the t) - the Central Airplane Intelligence system.
A couple of queries to CAI about her capabilites reveal that the setting is in the future and that she is capable of understanding natural language. And as it turns out, the first task of silencing the alarm is simply a matter of asking CAI to silence the alarm.
What the players don’t know is that the ultimate goal is to discover that the door will not open until the passenger manifest is “validated,” and CAI will not validate the manifest until all passengers are in their assigned seats. The only problem is that passengers don’t know what their assigned seats are.
The task then becomes a matter of finding all of the hidden boarding passes that associate passengers with their seats. Once the last boarding pass is located and the last passenger takes his seat, cameras installed in the seat backs finish reporting to the system that the passenger manifest is validated and the exit door opens.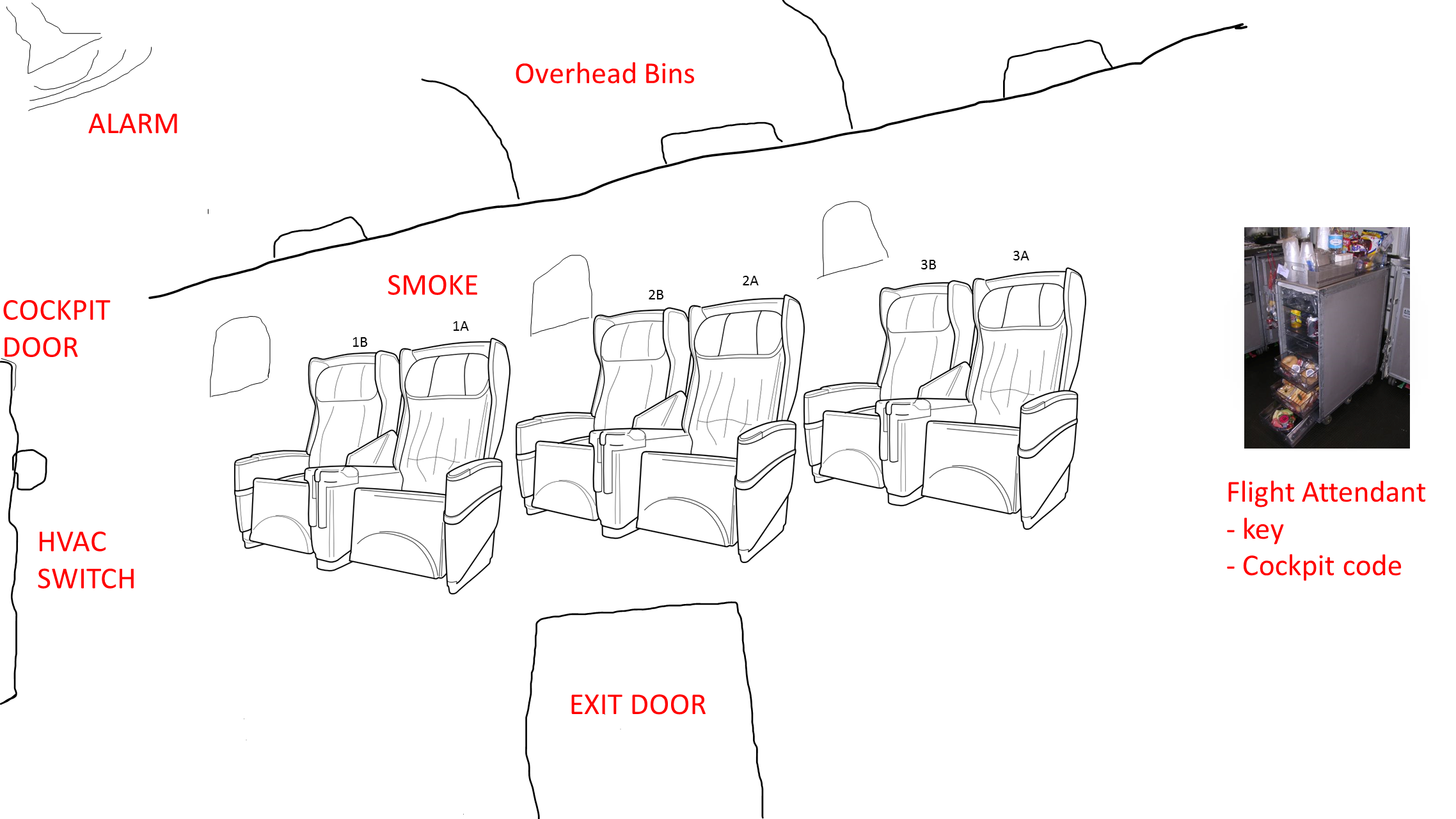
Architecture
Architectures of old were almost invariably n-tiered. We software developers are all intimately familiar with that pattern. Times they are a changing! An n-tier monolithic architecture may accomplish your feat, but it won’t scale in a modern cloud very well.
The architecture for cabin escape uses a smattering of platform offerings. What does that mean? It means that we’re not going to ask Azure to give us one or more computers and then install our code on them. Instead, we’re going to compose our application out of a number of higher level services that are each indepedent of one another.
Let’s take a look at an overall architecture diagram.
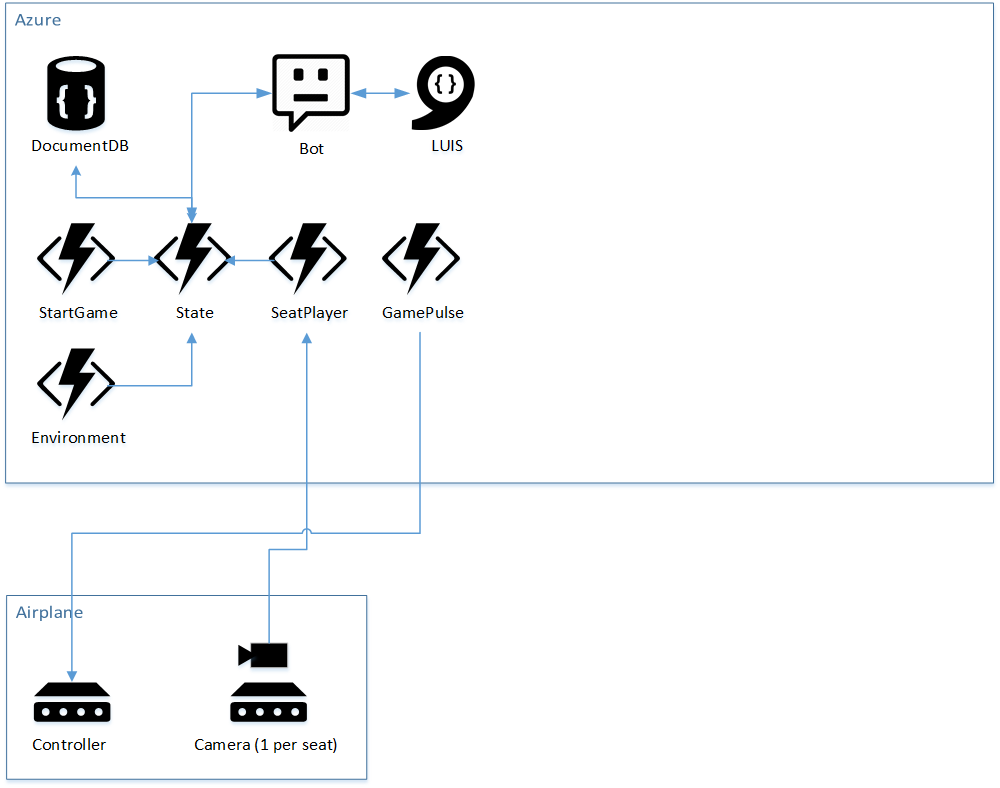
In Azure, we’re using stateless and serverless Azure Functions for business logic. This is quite a paradigm shift from classic web services are often implemented as an API.
API’s map to nodes (servers) and whether you see it or not, when your application is running, you are effectively renting that node.
Functions, on the other hand do not conceptually map to servers. Obviously, they are still running on servers, but you don’t have to be in the business of declaring how Functions’ nodes scale up and down. They handle that implicitly. You also don’t pay for nodes when your function is not actually executing.
The difficult part in my opinion is the conceptual change where with a serverless architecture, your business logic is split out into multiple functions. At first it’s jarring. Eventually, though you start to understand why it’s advantagous.
If any given chunk of business logic ends up being triggered a lot for some reason and some other chunk doesn’t, then dividing those chunks of logic in different functions allows one to scale while the other doesn’t.
It also starts to feel good from an encapsulation stand point.
Besides Functions, our diagram contains a DocumentDB database for state, a bot using the Bot Framework, LUIS for natural language recognition, and some IoT devices installed in the plane - some of which use cameras.
Cameras and Cognitive Services
The camera module is developed with Microsoft Cognitive Services, Azure functions, Node.js, and Typescript. In the module, it performs face training, face detection, identification, and as well as notification to Azure function service. The module determines if the right person is seated or not, then the notification will send back to Azure function service and then the controller decides the further action.
The following digrams describes the interaction between the Azure fuctions services, Microsoft cognitive services, Node server prcessiong and client.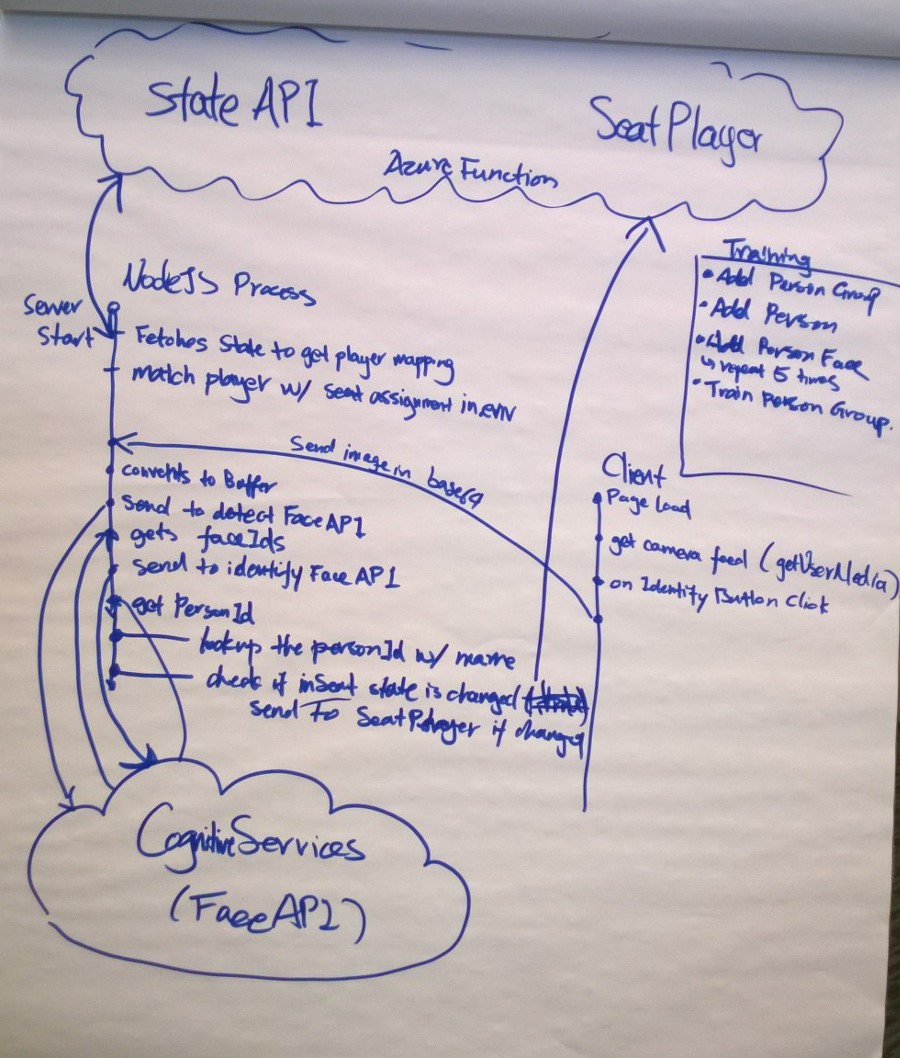
Cloud Intelligence and Storage
We use Azure Functions to update and retrieve the state of the game. Our Azure Functions are stateless, however we keep the state of every game stored in DocumentDB. In our design, every Cabin Escape room has its own document in the state collection. For the purpose of this project, we have one escape room that has id ‘officialGameState’.
We started by creating a ‘GameState’ DocumentDB database, and then creating a ‘state’ collection. This is pretty straight forward to do in the Azure portal. Keep in mind you’ll need a DocumentDB account created before you create the database and collection.
After setting up the database, we wrote our Azure Functions. We have five functions used to update the game state, communicate with the interactive console (Central Airplane Intelligence - Cai for short), and control the various systems in the plane.Azure Functions can be triggered in various ways, ranging from timed triggers to blob triggers. Our trigger based functions were either HTTP or timer based. Along with triggers, Azure Function can accept various inputs and outputs configured as bindings. Below are the functions in our cabinescape function application.
- GamePulse:
* Retrieves the state of the plane alarm, exit door, smoke, overhead bins and sends commands to a raspberry piece
* Triggerd by a timer
* Inputs from DocumentDB
- Environment:
* Updates the state of oxygen and pressure
* Triggered by a timer
* Inputs from DocumentDB
* Outputs to DocumentDB
- SeatPlayer:
* Checks to see if every player is in their seat
* Triggerd by HTTP request
* Inputs from DocumentDB
* Outputs to DocumentDB and HTTP response
- StartGame:
* Initializes the state of a new game
* Triggered by HTTP request
* Outputs to DocumentDB and HTTP response
- State:
* Update the state of the game
* Triggered by HTTP request
* Inputs from DocumentDB
* Ouputs to DocumentDB
A limitation we encountered with timer based triggers is the inability to turn them on or off at will. Our timer based functions are on by default, and are triggerd based on an interval (defined with a cron expression).
In reality, a game is not being played 24/7. Ideally, we want the timer based functions triggered on when a game starts, and continue on an time interval until the game end condition is met.
The Controller
An escape room is really just a ton of digital flags all over the room that either inquire or assert the binary value of some feature.
- Is the lavatory door open (inquire)
- Turn the smoke machine on (assert)
- Is the HVAC switch in the cockpit on? (inquire)
- Turn the HVAC on (assert)
It’s quite simply a set of inputs and outputs, and their coordination is a logic problem.
All of these logic bits, however, have to exist in real life - what I like to call meat space, and that’s the job of the controller. It’s one thing to change a digital flag saying that the door should be open, but it’s quite another to actually open a door.
The contoller in our solution is a Raspberry Pi 3 with a Node.js that does two things: 1) it reads and writes theh logical values of the GPIO pins and 2) it dynamically creates an API for all of those flags so they can be manipulated from our solution in the cloud.
To scope this project to a 3-day hackathon, the various outputs are going to be represented with LEDs instead of real motors and stuff. It’s meat space, but just barely. It does give everyone a visual on what’s going on in the fictional airplane.
The Central Airplane Intelligence (Cai)
This is a unique “Escape the Room” concept in that it requires a mixture of physical clues in the real world and virtual interaction with a bot. For example, when the team first enters the room, the plane has just “crashed” so there is an alarm beeping. This is pretty annoying, so people are highly motivated to figure out how to turn it off quickly. A lone console is at the front of the airplane, and the players can interact with it.
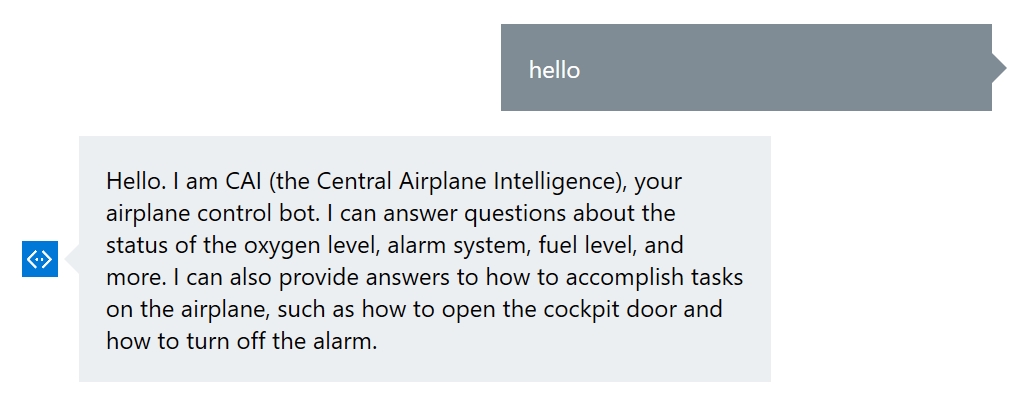
One of the biggest issues with bots is discoverability: how to figure out what the bot can do. Therefore, good bot design is to greet the user with some examples of what the bot can accomplish. In our case, the bot is able to respond to many different types of questions, which are mapped to our LUIS intents:
- What is the plane’s current status overall?
- How do I fix the HVAC system?
- What is the flight attendant code?
- How do I get out of here?
- How do I unlock the cockpit door?
- How do I open the overhead bins?
- How do we clear all this smoke?
- What is the oxygen level?
- How do I disable the alarm?
The bot (named “CAI” for Central Airplane Intelligence) was implemented in C# using LUIS. The code repository can be found at https://github.com/cabinescape/EscapeTheAirplaneBot.
The Git Add Patch Command
When you’re using Git for your version control, each commit should be atomic and topical. That is, it should contain related changes and nothing but related changes.
You don’t commit something broad in scope like “changed all the necessary files to implement feature 712”. That’s what a branch is for. Instead, you commit something like “added fetch() method call to the orders page”. That’s likely just one small part of feature 712. A whole bunch of commits end up implementing the feature.
But what about when you’re working away like crazy on your code base and you end up changing a single file in two different places and these two changes relate to different commits? Most people just go ahead and roll the changes into the same commit. Not ideal.
The hard way to do this right is to delete one change, stage and commit, and then paste the change back in.
There’s an easier way though. It’s called a patch add, but I like to call it a partial add. git add -h will show you the -p argument and inform you that it allows you to “select hunks interactively”. As much as that sounds like an online dating service for women, its actually just a really easy way from the command line to stage portions of a file and not the entire file.
Let’s say we start with this file…
//foobar.js |
Now let’s say I end up editing both of the functions in that file, but these changes are unrelated to one another. I simply changed foo to foo foo and bar to bar bar. Let’s look first at using the command line to take care of business here, and then we’ll try it with Visual Studio Code.
Here’s the changed file contents…
//foobar.js |
Command Line
Type git diff…
C:\scratch\foobar [master]> git diff |
Now to actually start the staging command, we type git add foobar.js -p and get the same diff along with these interactive options…
Stage this hunk [y,n,q,a,d,/,s,e,?]? |
There are actually a few more options than what are listed there too. You can type ?<enter> to get help on what those mean, but to spare time they are…
| Command | Action |
|---|---|
| y | stage this hunk |
| n | do not stage this hunk |
| q | quit; do not stage this hunk or any of the remaining ones |
| a | stage this hunk and all later hunks in the file |
| d | do not stage this hunk or any of the later hunks in the file |
| g | select a hunk to go to |
| / | search for a hunk matching the given regex |
| j | leave this hunk undecided, see next undecided hunk |
| J | leave this hunk undecided, see next hunk |
| k | leave this hunk undecided, see previous undecided hunk |
| K | leave this hunk undecided, see previous hunk |
| s | split the current hunk into smaller hunks |
| e | manually edit the current hunk |
| ? | print help |
Which to choose? Well, the diff that we see on the screen shows both changes. That’s too much. So we want to press s to split this hunk. That gives us…
Stage this hunk [y,n,q,a,d,/,s,e,?]? s |
…where now only one of the changes remains and we have our same interactive prompt.
The change we’re looking at is entirely related and should be in a single commit (along with possibly some other files). So we press y to stage it and then q to quit and we’re finished.
Visual Studio Code
Now let’s do the same thing using Visual Studio Code. This and a few other git-enabled IDE’s are smart enough to let you do a patch add. VS Code doesn’t call it a patch add though. It calls it staging selected lines, which actually makes good sense.
Start with the same file and changes, and view the changed file in VS Code and you should see…
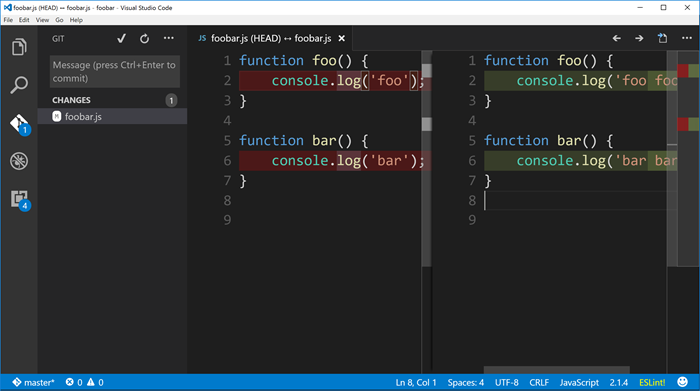
Now just put your cursor anywhere within the first change in the pane on the right and then find the little ellipse (...) on the top right corner of the window. From there choose Stage Selected Lines.
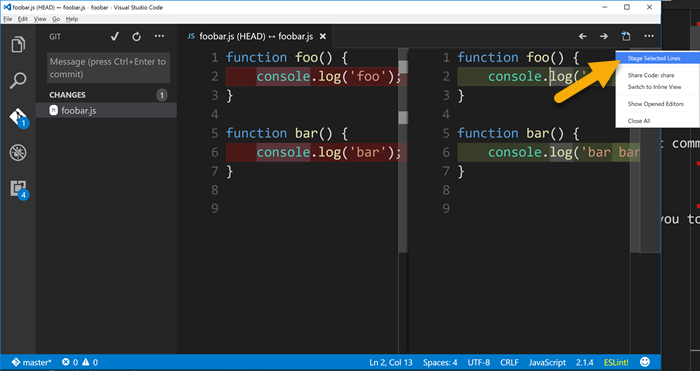
And then if you look in the Git panel, you’ll see that the foobar.js file has been staged but it also has changes that have not yet been staged.
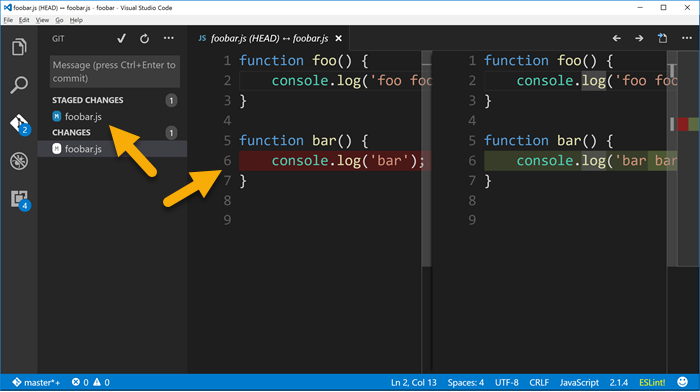
Whether you used the command line or Visual Studio Code to stage that first change and commit, you can just go about staging and committing the rest of the file as you normally would.
The end.
One Sweet Stack
Following is a mongo post. A huge post. A massive amount of information. The general recommendation is that blog posts should be short, but rules are made to be broken. You can’t tame me. I’m like a wild stallion. So here is a huge blog post.
Last Saturday at the Seattle Code Camp I delivered a presentation I called One Sweet Stack which showed how to start with a SQL Azure database (though it would work with any relational database really), connect to it using Entity Framework, and extend it as OData with WCF Data Services.
I chose this stack because…
- I come from corporations that have existing database solutions. These aren’t modern, green-field databases of the myriad of flavors. These are classic, tried-and-true, and very much relational. I’m as excited as the next guy all of the modern ways to persist data, but don’t think for a minute that the relational database story is obsolete. Far from it.
- I love using Entity Framework. I get a little jolt of excitement when I instantiate a DbContext or call SaveChanges(). Geeky? Of course.
- I think that WCF DS is oft overlooked and recently especially in light of WebAPI (which is also a great product). I’m a fan of designing a database, mapping it through an ORM, and providing an elegant API (whether it’s internal or external) with so little code that I can write it from scratch in a 1 hr session (including explanations).
- Windows 8 thrills me even more than EF.
I’m hoping to convey virtually all of the content from the presentation here, so it will be a heavy post. Consider it a reference post and come back to it if/when you need it.
The source code for this project is attached. You can find it at the bottom of this post.
First, the database…
So, as I said, I started with a SQL Azure database.
You connect to a SQL Azure database using a regular connection string just like any other database, so it will be a no-brainer for you to read this and apply it to a SQL Server on premises or even a MySQL or an Oracle database.
My database is a simple schema. It’s just a table of a few attractions that one will find on the island of Kauai, Hawaii and one related table of categories those attractions fall into (i.e. waterfall, scenery, flora, etc.). Here’s a diagram…
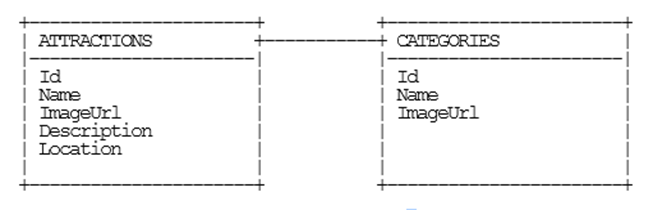
(my diagram by the way was done using asciiflow.com… very geeky indeed)
In the attached zip file, you’ll find KauaiAttractionsAzureScript.sql that you can use to create this database on your own Azure (or local if you’d rather) instance. Just create the database first and then run the script in the context of your new database. If you want to run through this whole exercise connecting to your own database, however, I would highly recommend it. It would be good practice.
Next, setting up the solution…
Follow these mundane steps to get over the snoozer that is creating projects, adding references, and importing packages…
- Create a new solution in VS2012
- Add a new Windows Class Library using C# (call it SweetStack.Entities)
- Add a new WCF Service Application using C# (SweetStack.Service)
- Add a new Cloud project using C# (SweetStack.Cloud)
- Add a new Unit Test Project using C# (SweetStack.Tests)
- Add a new Navigation App for JavaScript Windows Metro style (SweetStack.Metro)
- Add a reference to SweetStack.Entities to the .Service and the .Tests projects
- Add the .Service project as a web role to the .Cloud project
- In the .Cloud project right click Roles
- Add | Web Role Project in Solution…
- Choose the .Service project
- Add the latest version of Entity Framework (currently 5.0.0-rc) to the .Entities, .Services, and .Tests projects
- Add the latest version of Microsoft.Data.Services (currently 5.0.1) to the .Services project
Next, creating the .Entities project…
We have our database already in place, and now we want to create an Entity Framework context that will allow us to access our database using code.
Instead of creating an EF model (.edmx file), we are going to reverse engineer the database to POCO classes. Why? Because it’s rad. That’s why. First thing you need to do is install the Entity Framework Power Tools Beta 2 (from Tools | Extensions and Updates in VS2012).
Once that is done, you can right click on your .Entities project and choose Entity Framework | Reverse Engineer Code First. Then enter your connection string information. Remember to check the “Remember my password” box so that it will save your credentials into your connection string for later.
So the tooling should have created a bunch of .cs files in your .Entities project. You not only get POCO classes for each of your database tables, you also get one for the context. That’s the one that derives from DbContext. You also get a folder with a map file for each entity.
All of this is beautiful and I’ll tell you why. You now have a direct 1:1 relationship between your code and your database, but you also have the complete freedom to modify the mappings so that the two don’t necessarily match. If your data architect, for instance, called the database table “first_name” and you’d rather that be called FirstName in your code, then just change that property but keep the mapping to “first_name”. You can even ignore certain properties or add new ones that don’t have a mapping. Furthermore, classes that DO have database mappings can be mixed with other classes that do NOT have mappings. It’s all up to you.
Next, let’s test it…
It’s hard to see a Windows class library work without writing a test for it. In the .Tests project write a simple test that looks something like this…
[] |
Before you can run the test, copy the <connectionstrings> element from the app.config, create a new app.config in the .Tests project (right click Add New Item…), and then paste the
That test should pass if you haven’t mucked anything up already.
Next, time to create the .Service…
This one just FEELS like it’s going to take a while. Low and behold, however, I bet I could do it in less than 37.5 seconds (not that I’ve timed myself). Do this…
- Delete (from the .Service project) the IService1.cs and Service1.cs files that you got for free (even though you didn’t ask for them :)
- Right click the .Service project and add a new item… add a WCF Data Service called Entities.svc
- Once your file is created, check out the class name and see how it derives from DataService
but the T is undefined. Fill that in with SweetStack.Entities.Models.KauaiAttractionsContext - Now uncomment the line in the InitializeService method that says SetEntitySetAccessRule and in the quotes just specify an asterisk (“*”). You can change the EntitySetRights.AllRead to .All if you like, but we won’t be writing any data in this tutorial anyway, so it doesn’t matter so much.
- Copy the
element from the app.config of the .Entities project into the web.config of your .Service project - Put your hands down… you’re done!
Set your .Service project to the startup project and run it. You should get a browser that looks like this…

Note: if you get a list of files instead, just click on the
Entities.svcfirst.
Next, we let’s see what we’ve got…
What you’re looking at there is a GEN-YOU-WINE OData feed. That’s exciting. OData rocks. Not only do you get all of your entities extended through OData, but you get type information about them and you get their relationships with each other. Also, you can ask an OData feed for XML or for JSON and it will say “Yes, sir/ma’am.”
Fire up Fiddler and hit that service root URL appending each of the following and see what you get for responses (also add “Accept: application/json;odata=verbose” to the headers in Fiddler to request JSON). Issue the following commands against your service and behold the results…
<table border="0" cellpadding="2" cellspacing="0" style="width: 825px;"> |
If that doesn’t turn your crank then you should check your Geek card… it might be expired.
Next, we go Metro…
We’re ready to consume our data. We’re going to be working here with an HTML/JS Metro application which makes it reasonable brainless to consume JSON. Here we go…
I had you create your Metro app from the navigation template, so you should have a pages folder (assuming your using Visual Studio 2012 as opposed to Visual Studio 11). In there you have home.html, home.css, and home.js. Those three files are all we’re going to concern ourselves with for now.
In the .html file, you need to create a ListView and define an item template and a header template (because we want our items to appear in groups). Here’s what that would look like…
<div id="itemtemplate" data-win-control="WinJS.Binding.Template"> |
Then in the .css file add the following so that our images are the right size and our ListView is tall enough to show two rows…
.homepage section[role=main] { |
Finally, in the .js file we need to add just a little bit of code. I’ll just drop it all on you and then explain each section. Put this inside the page’s ready method…
var attractionsListGrouped = new WinJS.Binding.List().createGrouped( |
The first part (var attractionsListGrouped...) creates a new WinJS.Binding.List that groups the items by their .Category.Name. This necessitates that we bring our Attraction entities down with that $expand property included to get the related Category, but that’s easy so we worry not.
The next part imperatively sets the item and header templates and the data sources of both the items and the groups. This can be done before our list has even been populated with any items. In fact, we need to do it that way because the call we make to get the items is asynchronous and we need that list that we’re binding to to exist before we even get back from that call.
The last part is the xhr call. You can see the syntax. The xhr expects an object within which we’re specifying the url and a custom header. The function we pass in to the subsequent .then is going to run after we get back from the xhr call. At that point, we can look at the response, parse it as JSON, and then for each item, push it into our list. This list is a WinJS.Binding.List which means that it is essentially observable and will tell the UI when updates have been made so it can change accordingly. So when our items are fetched and filled in, the user will see them pop into the ListView in his view.
Tangent about application/JSON;odata=verbose…
Remember how we added application/JSON;odata=verbose to our headers for the xhr call? Why would we do that? It’s because we’re using the prerelease version of WCF DS, and the existing OData JSON syntax has been dubbed “verbose” to make room for some awesome new methods for expressing rich, typed, interrelated OData while keeping the payload light, light, light. More on that at a later time.
Conclusion
Attached you’ll find the complete source code. Hope it helps you learn Windows 8 development and I hope you get your first app done soon and are rewarded with huge royalty checks :)
And that does it for this walk through. It was a marathon post, so if you’re read this far email me your mailing address and I’ll send you a gift in the mail. I’m betting I won’t be troubled to send too many gifts :) (offer expires the end of June 2012)
Which Windows 8 Language Stack Should I Choose?
I had a conversation with an attendee at the recent Windows 8 developers event at LA Live on Monday that I want to put into words and share in case it is of benefit. The question was this:
I’m new to development and I’m jumping in to Windows 8 development. Which language stack should I choose – HTML/JavaScript or XAML/C#?
It’s a good question because there are a lot of contributing factors.
I’ll leave the other languages (Visual Basic, C++) out of the discussion for the most part since they were not part of the question.
Here are the factors I’d like to compare on:
- viability of employment
- scale
- interoperability
- developer joy
Finally, a direct comparison is difficult because the nature of each of these language stacks tends to push developers into application architectures. XAML/C# applications tend to enable a developer to create a lot of custom business logic inside the application itself, whereas HTML/JS applications tend to encourage a developer to push the business logic up to a separate service to be consumed in a JSON feed for instance.
Let’s go.
Viability of employment
First of all, I have to say this. Don’t jump into application development with high hopes of being employable but without any passion for the trade. It won’t work. I would love to play guitar, but I can’t. Why? Because I don’t love it enough. If I loved it enough I’d practice it every day and then I’d become really good. I guess my analogy breaks down there, because I wouldn’t necessarily be employable :) You really need to love software development and you need to do it every day. You need to read programming books in bed and you need to experience genuine, heart-felt aggravation when things aren’t working.
But it’s good to be employed, right?! Still, I don’t think viability of employment (now and in the future) is too much of a concern. Given the current developer and consumer investments in HTML and JavaScript as well as XAML and C#, none of these languages are going to leave their developers on the street any day soon.
If, however, you want to be a very portable employee, you should choose HTML and JavaScript. I’m not talking geographically portable but technically portable – as in, you want to work in a variety of roles at a variety of companies doing a variety of things. The HTML and JavaScript languages are everywhere. We don’t just have browsers on our computers anymore. There are browsers in cars and kitchens and phones. So, every role in every company in every industry needs to know something of these technologies.
Still speaking technically, the employment options for a XAML/C# developer are going to be more narrowly defined.
Scale and maintainability
When I say scale, I’m talking about the ability for an application’s code base to go from small to huge. You might consider this dynamic if you suspect your application will be growing a lot - say going from 3 features to 30. In this case, your codebase needs to grow and your architecture needs to evolve.
On the UI side, I can’t see any advantages of either XAML or HTML in this area. Behind the scenes, however, C# has some huge advantages over JavaScript. I’ve seen C# codebases that are mind boggling and yet still quite easy for the developer to traverse and debug. Handling a huge JavaScript applications on the other hand is about like handling Jell-O - both are a little too dynamic. That’s not to say it can’t be done; I’d never make that claim.
Interoperability
How good are these language stacks at cross communicating with other applications? Both are very good. You might want to jump in here and tell me how much better JavaScript is because of it’s lightweight JSON objects, integration with the web applications, and the like. But C# can do all of that too. Any of the C# objects are one small serialization step away from becoming the same JSON object that a JavaScript app uses and likewise in the other direction. Just because your C# application is fat with business logic, doesn’t mean it can’t communicate lightly with the outside world.
Developer Joy
This is an important category in my opinion. You don’t technically have to enjoy writing software to write a lot of good software, but it most certainly helps.
I find a lot of joy writing both C# and JavaScript. In C#, I enjoy the traversal of types, type hierarchy, and type conversion. I enjoy lambda statements a lot, and I really geek out on LINQ. In JavaScript, I enjoy JSON and dynamically creating, extending, and manipulating objects. I enjoy anonymous functions and passing them around willie nillie.
I think you have to run through some tutorials for each language and determine for yourself which one you might enjoy using more. The problem is that so much of my language enjoyment has come later when I’ve used a language for hundreds of hours and I’m starting to feel like I get it.
See if you can browse a bunch of JavaScript code and C# code and see if either feels more right to you. See if one of them comes more quickly to your intuition.
Conclusion
Overall, whatever language you choose for developing Windows 8 apps, you’re going to end up with the ability to create some awesome apps, you’re going to be employable, you’re going have fun doing it, and with the amazing opportunity you have to reach hundreds of millions of potential users, you are even likely to make some money!
Happy app development!
Ban the #Region
Just in case you didn’t know, you don’t need to use the #region designator any more to collapse code. When you use the #region indicator, you create a region for everyone you share your code with, and some people hate having regions in their files. I’m one of them.
If I’m looking at a code file that’s long enough to require regions, I’d rather not look at it at all. Even “in the real world” files should contain a single class, classes should follow the single responsibility principle, and methods should be short. If your code doesn’t look like that and you use regions to attempt to make your code remotely readable, that’s sinful enough, but to force those regions onto your fellow developers is just downright morbid.
How do you get away from them you ask? Simple. You just highlight code that you want to group and hit CTRL + M, CTRL + H (or the alternative mouse longcut of going to Edit | Outlining | Hide Selection). The code collapses just like a regions, but here’s the kicker – it’s only hidden for you! The change is saved in your .suo solution file which is for you only (never check this into source control), and now you can go ahead and collapse what you will and leave your fellows free to work how they will.
There you have it.
Insert Formatted Code into OneNote
If you haven’t started using OneNote, you might want to consider it. You can create a notebook a free instance of SkyDrive and it makes note taking, collaboration, and sharing all very easy. The part I couldn’t live without is my ability to just hit [WIN + N] from anywhere in Windows and instantly get a new note. I don’t have to worry about saving it either. By default, it lands in my Unfiled Notes (in my SkyDrive notebook). I can move it to another location later for more organization if I want to, but honestly the searching in OneNote is so good, that I usually don’t bother. As long as I give it a good title, I’m always able to find it later. Actually, even if you paste images into your note, the indexer recognizes the text in your image and will even search on that!
On my Windows Phone 7, I can do the same thing. I pin a “New Note” tile to my start page and I can just hit that to create an unfiled note. The great thing is that both notes land in the same place… on my SkyDrive. So if I jot a note from the field, it’s available to me in Windows on my laptop later. Nice.
But I’m a software developer and I write a lot of code. Sometimes I just jot down little pieces of code. So I went looking for a syntax highlighter that worked in OneNote. I found it. It’s called NoteHighLight and it’s on CodePlex (here). The installer is in an asian font, so it was a blind install for me, but just choosing the default button on each page of the install wizard worked fine.
It installs into OneNote as its own tab. I decided I’d rather have it in the Insert menu, so I customized it like this…

Hitting Insert and then choosing one of these will get you a dialog like the following…
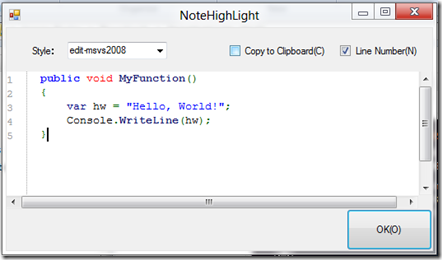
…and give you a nice way of typing or pasting in your code, and after completion, you’ll have something like this…
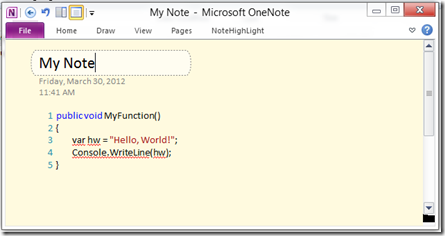
Happy note taking!