
The Azure CLI
At the time of this writing, there are two Azure portals you can use.
To get to the main, full-featured, current Azure portal, you browse to manage.windowsazure.com in any modern browser, and it looks like this…
The new portal is already available for you to play with and get familiar with, and it’s a good thing too since it takes quite a bit of getting used to. Once you grok it, though, I’m pretty sure you’ll like it better. You get to the new portal by browsing to portal.azure.com. Here’s what it looks like…

Both of these are works of modern, web art and very functional in my opinion. I love the current portal, and now that I’m accustomed to it, I love the new portal as well.
But I would like to get to the place where I have little to no need for the portals. I would like to instead to be utterly dependent on the command line.
I started some time back on the PowerShell command interface for Azure and it’s very well made. I had a hard time getting to it though. I suppose it was the long commands - the PowerShell syntax. Although it’s quite descriptive and offers good tab completion and documentation, I still found it a chore and kept at my work in the portal.
I had a glance some time ago at the node tooling for Azure as well, but didn’t really give it a fair shake. Now I’m shaking it like crazy and really excited. Check out some of these things you can do…
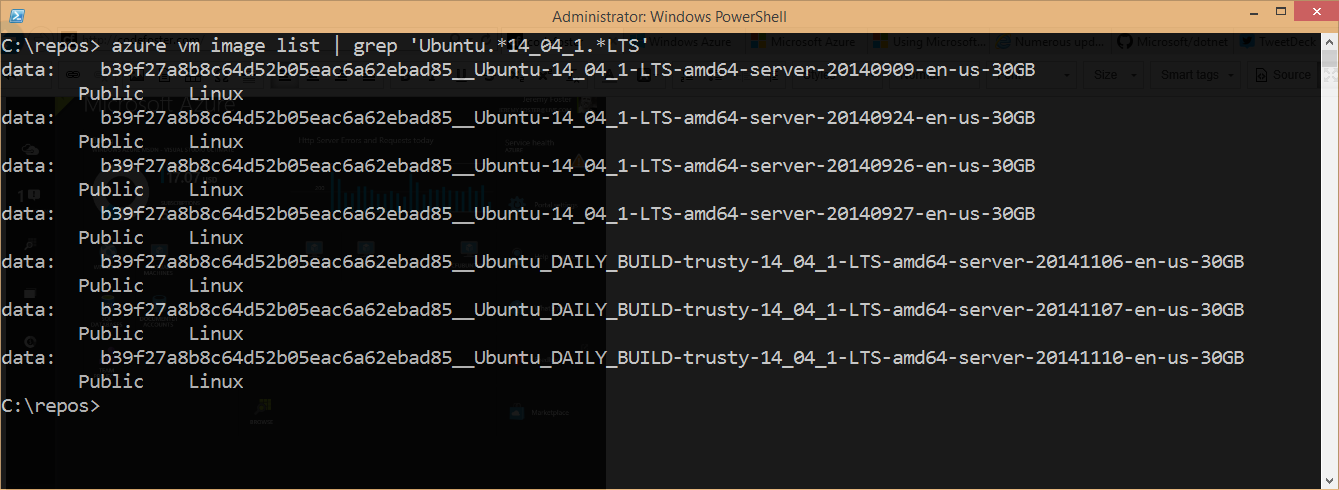
Check out which Ubuntu images I can use for creating a VM…
The following will generate a list of Azure VM images and allows me to pipe to a regular expression to pull out just the stable (LTS) Ubuntu images of a certain version (14.04.1). It’s also possible to add a --json property to the request and get this data back in JSON format.
azure vm image list | grep 'Ubuntu.*14_04_1.*LTS' |
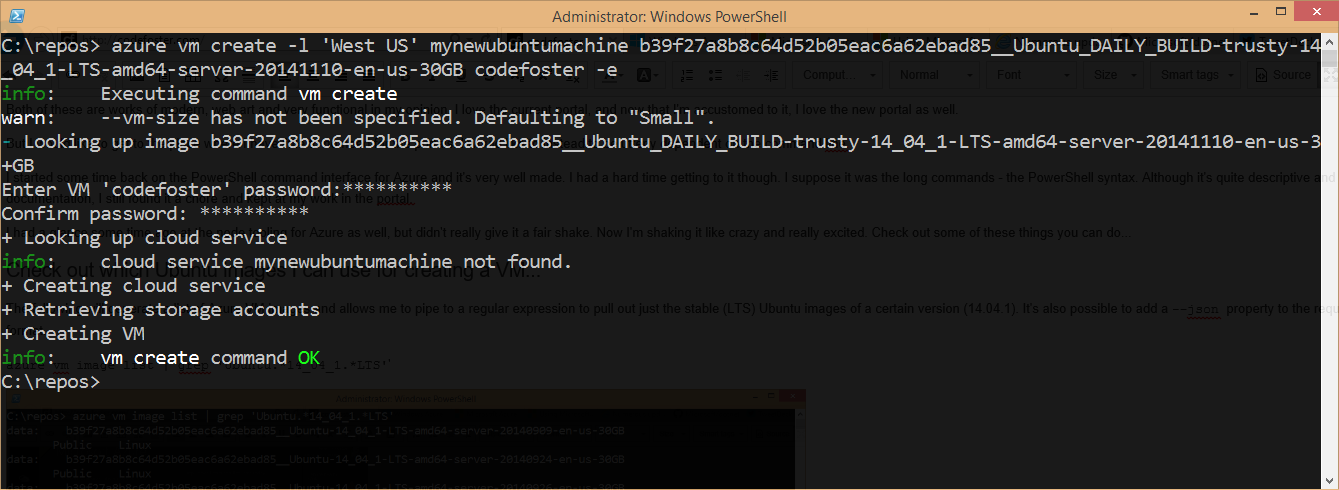
Create an Ubuntu Linux VM from one of those images…
Once I’ve chosen the image I want to start with, I simple call the following to create a new VM in the West US region. I add the -e parameter to add ssh capability so I can ssh into the machine when it’s finished.
azure vm create -l 'West US' VM_NAME b39f27a8b8c64d52b05eac6a62ebad85__Ubuntu_DAILY_BUILD-trusty-14_04_1-LTS-amd64-server-20141110-en-us-30GB codefoster -e |
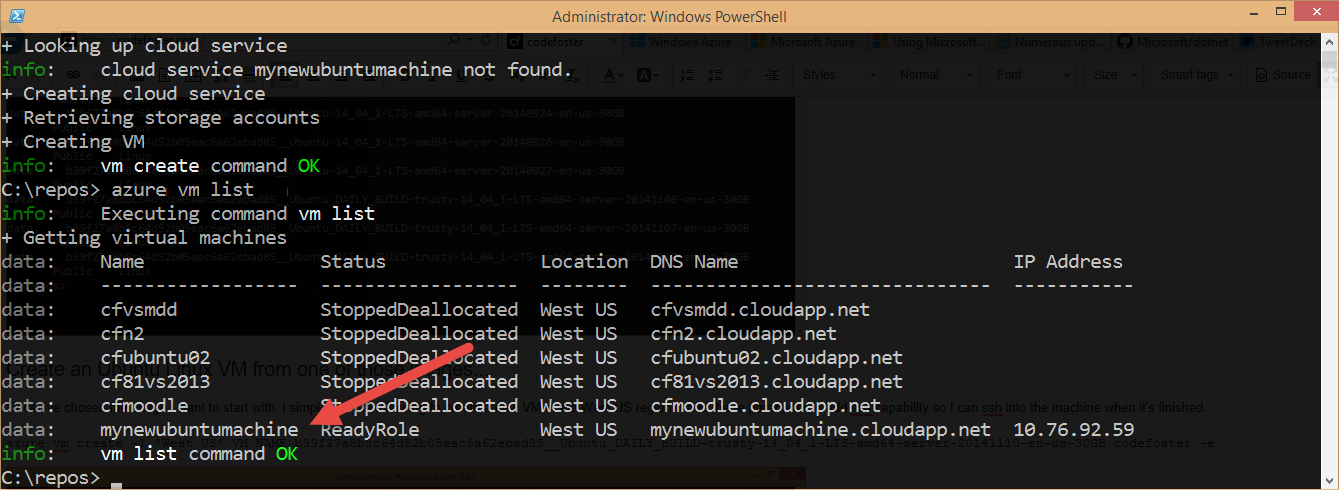
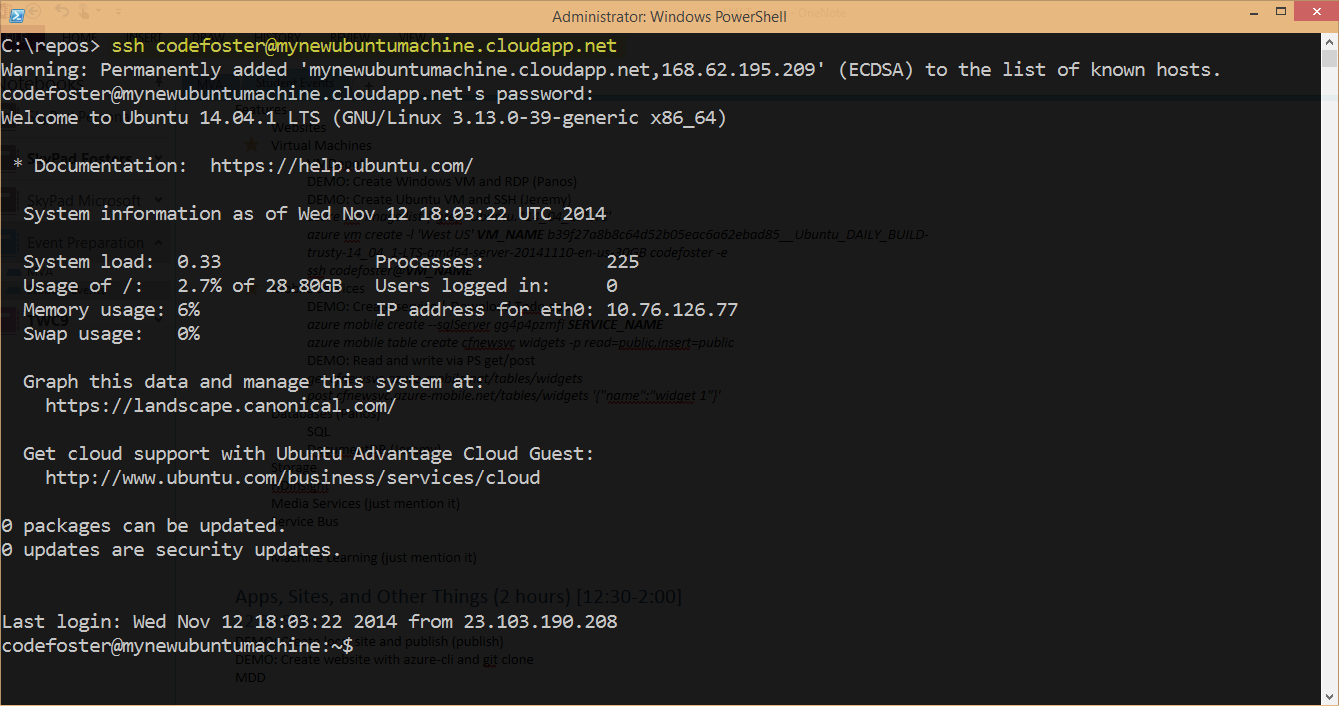
Now let’s fetch a list of my VM’s and see the new mynewubuntumachine in there…
By the way, if you’re like me and like staying in the command line interface, try installing Cygwin. It runs great in PowerShell and allows me immediately after creating this VM to ssh into it like so…
I’d rather that machine not start charging me for compute, so let’s shut it down and make it free (except for a little bit of storage… pennies)…
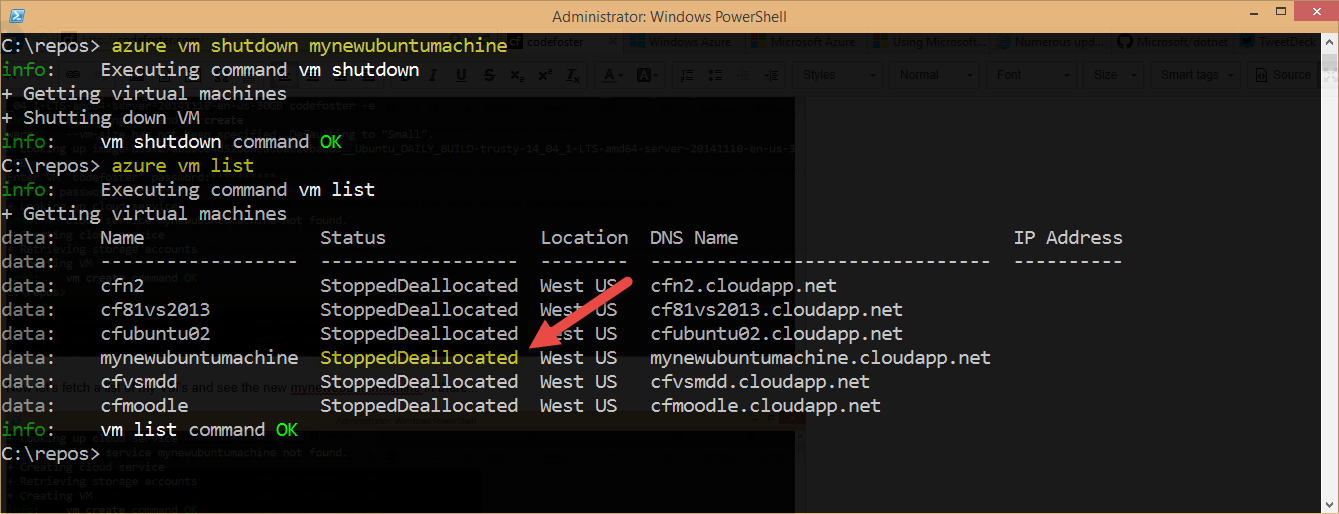
That’s better.
What else can we do with the azure-cli? Oh, man. Glad you asked. Let’s create a quick Azure Mobile Service, add a table, and then use some PowerShell candy to start writing and reading records.
Creating a Mobile Service…
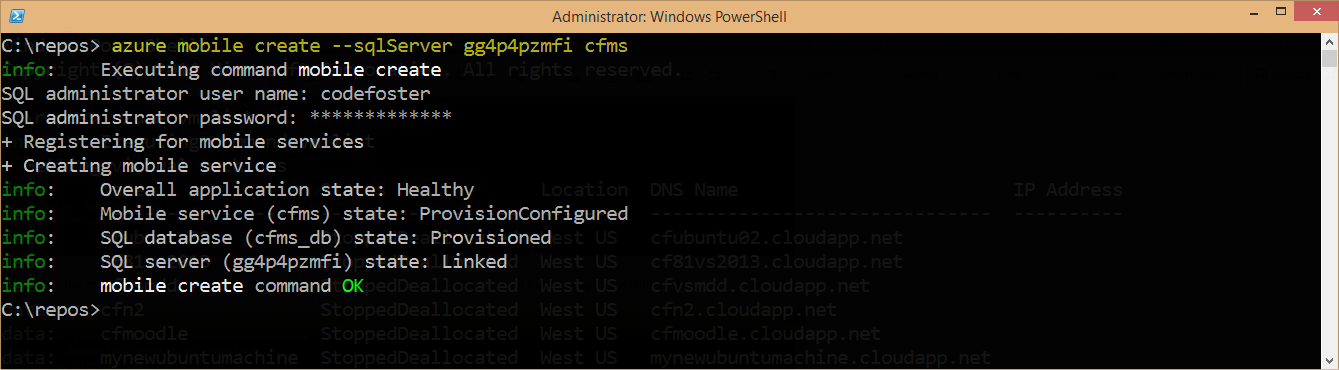
First, we create the service like the following where gg4p4pzmfi is simply the name of my particular SQL Server. I already have it, so I may as well use that instead of creating a new one. My service is actually going to be called “cfms”.
azure mobile create --sqlServer gg4p4pzmfi cfms |
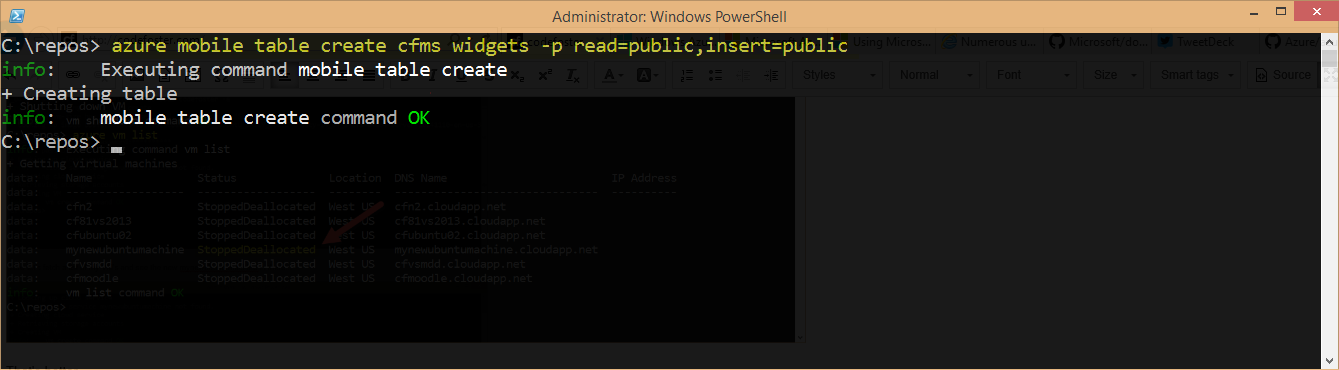
Then we create a table. Let’s just punt and call it widgets. In order to show interactions with the table via simple HTTP commands, I’m going to open up the insert and read permissions so I don’t have to create authentication headers in my HTTP calls…
azure mobile table create cfms widgets -p read=public,insert=public |
And there we have a service with a table ready for us. Now, in case you’ve never noticed, PowerShell natively allows us to use curl to do web requests, but curl is not really installed. Instead it’s a simple alias to the Invoke-WebRequest method in PowerShell. I chose to write the following functions into my PowerShell profile so it’s always available to me…
Function get ($uri) |
So now we can write a record into our new widgets table like so…
post [http://cfms.azure-mobile.net/tables/widgets](http://cfms.azure-mobile.net/tables/widgets) '{"name":"widget 1"}'; |

Do notice that the response we got back from this post included the actual inserted object complete with the GUID that Azure Mobile Services tacked on to it. In case you’re not already familiar with Mobile Services, you should also take note that we didn’t schematize this table when we created it. Instead, we simply created an object with a name property and let Mobile Services handle that for us.
Now, a get from the same table should show us our widget 1 record, and in fact it does…

I love how simple and elegant a solution this is.
There’s obviously a whole lot more we can do with azure-cli that I won’t take the time to detail. But there’s one more thing you should see - the inline help. For any command, simply tack on -h and you will get good information about the various possible parameters you can use. It’s contextual too. If you type azure -h, you’ll see all of the high level options for the azure-cli tool, whereas if you type azure vm -h, you’ll see specific commands for working with VM’s.
The azure -h is great for giving you an overview of what the tool will do.
I hope you have as much fun with this as I have already.
To get started, visit this page to see instructions on installing the tooling.
I had one gripe with the Microsoft Band... Now I have zero.
For the most part, I’ve been really enjoying the Microsoft Band that I bought the day they went on sale.
Like the rest of the world, I learned about the landing of some new Microsoft Health apps in the various app stores on Wed, Nov 29, and like the rest of the world, was thrilled to hear the next morning that they were available for sale. Serindipidously, I had broken my last watch (of 8 years!) only weeks before, and was holding out on buying a new one in case we released something. Then we did, so I was ready to buy.
Since my purchase, I have been continuously pleased to have certain bits of information on my wrist. I’ve never really had any useful information on my wrist before. Sure, I had a Casio Data Bank watch in the 80’s like any good geek.

But I’m talking about useful information. The difference between a helpful computer and a truly useful computer, in my opinion, has always been connectivity. A computer without connectivity is a glorified calculator. So there’s a big difference between my Data Bank and my new Band.
But I had one gripe.
My Band was not glancable. When I glanced at my Band, I saw a black screen. I assumed this was a concession that just had to be made because of battery, and I was okay with it, but I was slightly disappointed on a regular basis that I had something on my wrist, but was not able to have a glance and note the time. It was not just disappointing, but somewhat disorienting, since this glancing was a strong habit from the last 8 years with a normal watch.
There was one more caveat to my gripe. I didn’t have any way that I could find to see the date. Seeing the current date is a major use case for me. When I sign something at a register, I don’t have time to actually think about what the current date is, I like to simply have a quick look at my watch. The Band, however, didn’t have this information for me - it was just a black screen.
Sure, I found watch mode in the settings, but immediately made the wrong assumption. I assumed that watch mode was going to keep the screen on full all the time. Intuitively, that would be an unacceptable battery drain, and likely a bit of a distraction. Even if the screen were to remain on all the time, it wouldn’t solve the second part of my gripe - information about today’s date.
Recently I actually gave watch mode a try and am absolutely thrilled to realize that both of my problems are solved.

Certainly there will be an amperal impact to keeping certain pixels white 24/7, but my intuition tells me it won’t be much and my colleague Tobiah Marks tells me he’s been using watch mode and still gets at least 1.5 days. I don’t have any trouble, as I initially thought, finding time to charge my Band, so this is absolutely fine with me.
Watch mode actually works a bit like the much-loved glance feature on Microsoft’s Lumia phones - it blacks the screen and shows the time in white. In the case of the Band, it also shows the date. Now I have the time and date at a glance all the time and that makes me super happy. When I wake the Band up with a power button press, I still see the date on the main screen in place of the steps. In essence, then, watch mode has told my Band that I use my device a bit more like a watch than a fitness band. Which is correct in my case. I’m thrilled to have all of the fitness features, but primarily I want a watch that makes me feel like I’m on the Starship Enterprise.
Beam me up, Cortana.
The Place for Styles in HTML and XAML
I got a question from the community.
When working on a Windows app, how do you get a complete list of the style properties that apply to any given HTML element?
The short answer is you don’t. And that’s not a Windows thing, it’s an HTML/CSS thing.
With a language like XAML/C#, you have properties that apply to certain elements because of the way everything works behind the scenes. It’s all strong typed and inherited, so when you start typing the name of a property, Visual Studio is able to look into the typing system and see which properties apply and suggest them via Intellisense. But with HTML/CSS, the CSS properties don’t belong to certain elements. Instead any property can be applied to any element and it’s up to the browser (hopefully adhering to the standards) to implement what happens. Some are obviously ignored. It doesn’t make any sense, for instance, to set the font of an image, so the image element will simply ignore it. This is not really a big problem in my experience. You come to realize which properties have which effect on which element at the same time that you learn what the properties are and what they do. And they’re mostly intuitive. But we can thank the openness and democratic nature of HTML/CSS for the matter.
The best way to get a complete list of CSS in my opinion is to bookmark aka.ms/iedevcenter and then visit that and click on CSS under the Develop section.
And the second part of the question was…
Why is it never a good idea to inline style properties when using HTML/CSS. After all, in XAML, we often write the properties right there in the declaration of each element.
The fact is that in both HTML and XAML, you can choose to add your styles inline (that is, within the element in the HTML page), or at the page level (in a
Things a Web Developer Should Have Memorized
Web development involves the use of a lot of technologies and languages implemented according to a lot of standards. It’s not exactly the most cohesive stack and I would attribute that to its long and democratic evolution as well as its very broad acceptance and implementation.
At the end of the day, though, it leaves us web developers with a lot of information to wrap our heads around. It helps me to keep a bit of a reference sheet on the parts that I look up often, and even be sure that some of it is firmly committed to memory - my own L2 cache, if you will, to avoid even a glance at the reference sheet.
Here are some of the things on my reference sheet in case you find them helpful too. I’m thinking this will be a good canon of things a beginning web developer should learn as well.
URI Scheme
We take URI’s for granted, but we usually just take the simple form for granted and might see derivatives as proprietary hacks. In fact, the primary spec for URI’s is pretty robust and a lot of the derivatives you might run across are entirely valid. I helps to spend a second considering the full form and having a glance at a few examples so you’ll know how to recognize a valid URI.
<scheme name> : <hierarchical part> [ ? <query> ] [ # <fragment> ] |
The complete example that is given on Wikipedia is helpful here…
foo://username:password@example.com:8042/over/there/index.dtb?type=animal&name=narwhal#nose |
In this example, we’ve got a scheme name of foo. By the way, I’ve also heard this called the protocol. The one you see all the time is http.
We have a username and password of username:password. I use this commonly for passing credentials in to an FTP connection. Keep in mind there is no protection at all of this password. It’s passed in clear text and you should pretty much count these public credentials if you’re going to use it.
The domain, then, is example.com followed by a semi-colon (:) and the port number (8042), the full path (/over/there/index.dtb), an optional question mark symbol and query string (?type=animal&name=narwhal), and an optional pound symbol and fragment identifier (#nose).
There’s a lot more good information about URI schemes (and a few other topics :) in this Wikipedia article.
HTTP Request Methods
The HTTP request methods, which many like to call verbs, are a set of directives we get to pick from when we’re making a request to a web server. The directive tells the server something about the nature of our request, our agreement on the format and content of the request, and our expectation of the response. The list of verbs in rough order by popularity would be a good thing to commit to memory if you haven’t already. They are GET, POST, PUT, DELETE, PATCH, HEAD, TRACE, OPTIONS, and CONNECT. They are by convention capitalized and that makes it funny when you choose to shout them in the middle of an otherwise normal sentence.
If you can only memorize two of these, make them GET and POST which I would guess comprise about 98.5% of the HTTP requests currently flying around the internet.
GET. A request. A question. An attempt to convince the server to give me a representation of a given resource. If I ask for http://mydomain.com/mydocument.html via GET, I’m asking for the contents of the document itself to be sent to me.
POST. A request, but not so much a question. A POST is a way to submit new data to an existing resource (a collection for example). It’s very commonly used to receive form data.
If you want to play around with creating web requests and hurling them toward unsuspecting servers, I recommend downloading and installing Fiddler by Telerik. Fiddler makes it very easy to compose requests, analyze the results, replay requests, and tons more.
HTTP Status Codes
Memorizing the status codes is quite important. You never know when you’re going to be paired programming and get a 204 response back from a web service. In that moment, it’s going to be you against your partner and no matter how fast you’re able to get this Wikipedia article, it’s going to be much too late for your reputation. For the record, had a 204 been returned to me before I wrote this article, I would not have known it and would have been appropriately ashamed.
So make up some flash cards, hand them to your spouse and say “quiz me”. Use the full list from Wikipedia, but for the sake of completeness, a few of the important ones are listed below.
It’s certainly a bare minimum that you memorize the categories of status codes, which are…
| Code | Meaning |
|---|---|
| 1XX | Informational |
| 2XX | Success (yay!) |
| 3XX | Redirection |
| 4XX | Client Error (it’s your fault) |
| 5XX | Server Error (it’s their fault) |
If you get a 600 code, there’s really something wrong.
And here are a few of the codes that codefoster deems common or important…
| Code | Meaning |
|---|---|
| 100 | Continue |
| 200 | OK |
| 301 | Moved Permanently |
| 401 | Unauthorized |
| 403 | Forbidden |
| 404 | Not Found |
| 418 | I’m a little teapot (no joke… look it up) |
HTTP Header Fields
HTTP header fields are all of the things you get to sprinkle into your web request to be more specific about what you’re attempting to do with that request. And then they’re also sprinkled into the response back from the server. Most client SDKs that wrap HTTP calls provide the headers as a collection. This is basically so you can avoid writing regular expressions, and avoiding writing regular expressions is sort of the whole point of being a software developer I think.
There’s obviously way to many possible header fields to memorize, but I’ve found myself going back and looking up some of these a dozen times, which is far less efficient than just take a little time to commit the common ones to memory. You can get the complete (if that’s possible) list of fields on the Wikipedia article, but here’s what I recommend for learning the HTTP header fields that will be the most valuable for you. Use an HTTP sniffer like the one I mentioned already - Fiddler - and watch the requests and responses that are sent and received for some common traffic such as when you’re simply browsing the web or when you’re calling web services. Then make a list of all of the request headers and response headers you see go by and look them up on that Wikipedia article I mentioned and understand and memorize each.
HTML Header Information
There’s plenty to memorize within the context of the web platform languages - HTML, CSS, and JavaScript, but I won’t enumerate all of those here. I will, however list some HTML header information that I think is sort of cross-concern and would be helpful to have in your head.
Put all of the various HTML DOCTYPE formats out of your mind and simply memorize the one simple one that HTML5 gives us - that is…
<! DOCTYPE html> |
It’s by no means a complicated line, but for some reason I found it hard to memorize. I guess it’s due to how infrequently I actually have to write it and the strange syntax - <! prefix, no closing tag or self-closing tag, upper case DOCTYPE and lower case html.
You can look at the meta tags that are still popular such as keywords and description, but honestly I don’t think there are many more. The use of meta tags is declining I believe, and even the use of keywords and description - despite their purpose for improving SEO (search engine optimization) - supposedly has little to no effect.
Well, I hope this is helpful to have this information in one spot. Now, do what it takes to make sure that one spot is in your brain instead on this blog post.
12 Things to Do Before You Start a Presentation
I give pretty many presentations about things an aspiring developer might want to know - how to spin up a Node.js service, how to get web sockets firing, how to do some duck typing in JavaScript - you know, fun stuff.
Before I give a presentation, especially a bigger one, I open OneNote and have a glance at my Show Time Checklist to make sure I’m running on a well-oiled machine and have given myself the best chance at a snag free show.
Here’s my list in case it improves your life in some way…
- **Restart. **There’s nothing quite like a system restart. It’s the first thing I tell my grandma to do when things don’t work. What’s that, Grandma? You forgot your email password? Let’s go ahead and find that power button. I put a sticky note with an arrow on it last time I was visiting and you made me brownies.
- Open IDE’s I’m usually using some combination of Visual Studio, Notepad++, and the browser (I <3 CodePen.io) to write code. There’s a delay opening VS or N++, so I get those warmed up before I start.
- Uninstall previous trials. Sometimes I actually practice my presentation before show time… sometimes, and it’s always awkward when I have to create SampleProject2 because SampleProject always exists. It makes it look like I need to practice or something.
- Close all browser tabs. You know those tabs where you were looking up the answer to what you’re just about to teach others? Yep, close ‘em.
- Close everything. Close all the windows that you’re not going to use in the presentation. It’s obvious, but this list is a tickler, so I don’t have to think too hard, so I include it.
- Open emulators or simulators. They tend to take some time loading their OS the first time, so it’s good to have them open. If you’re showing an Android emulator, open it. It will still be slow, but anyway. :)
- Close your chat app. You should have already closed your chat app at step 5 when you closed everything, but this guy gets his own line because he’s a special offender. It’s awkward when your wife emails you a question from the pharmacy during your presentation!
- Get your emergency backup in your ALT + TAB. You should never show anything you don’t have a backup for. It’s a rule I break all the time, but that doesn’t make it any less of a good idea. If I’m showing how my brilliant code turns into a beautiful UI, I should be ready for it to turn into a brilliant mess and have a rendered PNG version at hand - you know, from when I practiced this.
- Pin presentation folder to Windows Explorer taskbar icon. I have a folder for every presentation with slide decks, code projects, etc. inside. I like to drag a shortcut to my Windows Explorer taskbar icon for show time. I can access it quickly with WIN + ALT + 4, since 4 is the position of my Windows Explorer shortcut on my taskbar. Yours might be different.
- Go to presentation mode. In Windows, hit your Windows key and type presentation. You should see Adjust settings before giving a presentation. That opens your Presentation Settings where you can tell Windows to suppress notifications globally. You can also turn off your screen saver, set the volume, and change your desktop background, all of which will be reverted when you are done presenting. Super handy. I’m not sure if MacOS has an equivalent.
- **Honey and water. **My throat loves to sabotage my efforts to speak. I keep honey packs in my bag and down one just before a show. It simultaneously sooths and delights.
- Take some breaths. Sounds trite, but this is a big one. The best thing you can do before a show is calm down. Make some small talk with the folks in the front row. If you don’t have something prepared at the last minute, is it really going to help to do it now? I doubt it.
And here’s the list without all of my banter in case you want to drag it over to your own Show Time Checklist in OneNote…
- Restart
- Open IDE’s
- Uninstall previous trials
- Close all browser tabs
- Close everything
- Open emulators or simulators
- Close your chat app
- Get your emergency backup in your ALT + TAB
- Pin presentation folder to Windows Explorer taskbar icon
- Go to presentation mode
- Honey and water
- Take some breaths
Feel free to drop a comment below if you have other ideas for how to prepare for the big hour.
Recursion Plain and Simple
I’m not setting out to explain recursion in full detail right now. I just want to do my best to relay the concept.
Recursion, in simple terms, is logic that depends on itself. I honestly can’t tell you whether it’s the simplest or the most complicated of concepts. It’s sort of both. Let me attempt to explain.
A typical programming function looks like this (in JavaScript)…
function f(a,b) { |
It receives some things (a and b) and it returns something (the sum of those). It starts when it is called and it ends when it returns. It’s as simple as that.
But a recursive function is one that calls itself. What?! It’s a little weird. Let’s try this…
f(1,1); |
Now, technically this is a recursive function, because it’s calling itself. But it’s not a very good one.
What’s wrong?
Can you tell what’s going to happen? It’s fun. It’s called a stack overflow. That is, when we call the function and it calls itself, that causes it to call itself, which causes it to call itself, which causes it to call itself, lather, rinse, repeat. Eventually (rather quickly actually) our system runs out of memory to hold this infinite stack of function calls and it throws an exception.
So, we successfully created a recursive function, but we didn’t limit it in any way. It’s like when you get a microphone too close to a speaker and it forms a feedback loop. Or it’s like when you plug a video camera into a TV and then point it at the TV. Or when you look in parallel mirrors just right. In every case, a somewhat perfect case is fulfilled. The output becomes the input… exactly as it is every iteration. The amplification continues, and you get strange and very extreme results.
Let’s change our function a bit so that instead of adding two numbers together, it simply takes a single number and then continues adding that number to itself minus one until it runs out of numbers (gets to zero). So you should be able to see that we now have a limiting case until we run out of numbers. That’s important.
f(17); |
Notice that the condition inside the function is asking if we reduce n by 1, is that still going to be bigger than zero?, and if it’s not (if n is 1 and thus n - 1 is zero) then we just return n. We don’t call ourselves again. That’s the critical piece. In order to avoid a stack overflow, there has to be some logic in your function that at some point allows the function to complete without calling itself again.
So, recursion obviously works great for finite mathematical operations like my example, but where else might you find this concept in the wild? The answer is all over the place. As it turns out, there are quite a lot of use cases. If you have ever worked with a folder structure or perhaps with a tree view control, you’ve likely discovered that recursion can turn hundreds of lines of code into a handful. Any data structure that contains an entity that can be involved as either the parent or child in relationships is inherently recursive. After all, who knows how deep the tree is? Who knows how many levels deep the relationships go?
I hope this helps you wrap your head around the concept of recursion. It’s a foundational one and mastering it gets you one step closer to being a computer scientist.
Web API or WCF... Which Way to Go?
Have you noticed the overlap between WCF and Web API? I did.
And not only have I noticed it, but I’ve watched both of the frameworks change so that the overlap between them evolved, and I’ve done my fair share of speculating about what the potential paths forward are and when to use which.
Overall, the story with WCF and Web API is a convergent and not a divergent one. The teams at Microsoft are completely unified and so is the strategy. Nevertheless, the two frameworks exist as does the overlap and developers’ various solutions using one, the other, or some combination, so a little discussion on the matter might be helpful. A smidgen of official guidance on the subject is available from Microsoft’s developer network in an article called WCF and ASP.NET Web API, but it is by no means wordy and leaves a lot of architectural concepts and decisions to you, the developer.
I’ll try to be more specific and prosaic on the matter, but I won’t obviously be able to make any decisions for you, especially where existing solutions are already in place. I can, however, let you know a bit more about where Microsoft is on the matter and where I am as well and you can use your own noodle and your own intimate knowledge of your problem space to make the best decision. After all, that’s what they pay you for, right?
After reading this brilliant discourse on the topic, I highly suggest you take the time to watch Daniel Roth at TechEd North America 2013 present Serious Web Services. You’ll walk away from that an expert.
Guidance… Choose Web API (if you can)
Here’s where I advise you start - if you can choose Web API, choose it. You can choose Web API if the following are true for you…
- You can stick to the HTTP protocol. HTTP is a layer above TCP. That means that is uses TCP, but it adds some stuff. In adding some stuff it makes the communication just a tiny bit slower. Here’s a typical envelope for an HTTP request…
GET /mypath/myendpoint HTTP/1.0 |
…and for a response…
HTTP/1.0 200 OK |
The round trip in total is not that large, but if you’re talking about 10’s of thousands of messages then it might become a consideration. Using HTTP messaging is hugely convenient in a number of ways - not the least of which is the practically instant compatibility with a lot of client systems. Everyone these days speaks HTTP with a wide variety of helper classes out there. If you’re in JavaScript you have jQuery’s ajax(), WinJS’s xhr(), and likely about a billion more. If you’re in C# you have the HttpClient helper class. Even if you don’t have any helpers, composing a text message like the sample above wouldn’t be rocket science (unless of course you’re in the aerospace industry).
WCF can speak HTTP, but it can speak a number of other protocols as well. The cool part is that all of the work you do to define your entities and your operations is independent of the transport protocol too. That means you can talk HTTP to some clients and straight TCP to others. That’s a big advantage.
If you know, however, that you can get away with only talking HTTP, then read on and keep on considering Web API.
- You don’t have a requirement to support SOAP. HTTP is an envelope on TCP. SOAP (Simple Object Access Protocol) is another envelope on that - on top of HTTP. And it’s a significant one too. Look at this SOAP message. Yowzer! And this is the best case scenario. Actual implementations usually end up with a lot more piled on top.
POST /mypath/myservice.asmx HTTP/1.1 |
As you may spot immediately, SOAP is XML, so besides its inherent, relative verbosity, it is also subject to the verbosity of XML. When you have to <thing> wrap all the things </thing>, they start to get pretty long, n’est pas? SOAP is the foundation of the WS* stack - a suite of standards to determine one way to implement web services. The problem is the WS* stack is pretty thorough and pretty pervasive in the enterprise. So if you’re an enterprise developer trying to introduce some agility to your group, you may run up against the constraint of having to speak SOAP.
- *You don’t need Reliable Messaging, WS-Transactions, or any of the other WS junk. **Web API implements web services using a variety of primitive and largely preexisting protocols such as HTTP, WebSockets, and SSL, so you don’t get the various higher level protocols such as RM or WS-Transaction. You don’t get the power of those protocols, but you also avoid the headache in my opinion. I have always felt the process of implementing such protocols was relegated either to suspicious black magic libraries or pain staking implementation ceremony.
There may be more, but those are the basic constraints I can come up with on a moment’s notice.
OData
It seems like everyone is talking about the raw and simple HTTP REST JSON approach, and that’s great, but there are a couple of other approaches to consider. One of them is a shaking of even the HTTP protocol. You can accomplish that by embracing web sockets. You can implement an entire API using Signal R and it would surely be very fast and very impressive. Another alternative is to keep the HTTP envelope but get more specific with your data format specification by embracing OData. A client can look at any OData set of data with standard tools or code because they’re always formatted the same. Additionally, OData allows me to query my data with clever URL strings so I only get back the data I want. OData is nifty. Here’s a simple HTTP request to an OData resource…
GET /mypath/widgets?$filter=name eq Widget1&$select=id HTTP/1.0 |
This is a simple GET to an OData resource (a collection of widgets it appears) that will take only the id column of the widget with the name “Widget1”. So that is going to return a microscopic result that looks something like…
{"id":17} |
I used to consider it a strong advantage of WCF that I was able to create a WCF Data Service (a simple class inheritance), point it to a compliant data service (such as an EF DbObjectContext), and presto I had a full OData implementation of my dataset. It’s a great party trick (depending on the party), but Web API has matured to the point where the same solution (a very useful OData feed from a dataset) takes hardly any more effort and has the added advantage that it uses scaffolding so my service implementation is not hidden behind the façade of the WCF DataService class. Additionally, (and of critical importance) the WCF team has put some guidance out there that WCF Data Services is not the way forward. They’ve done a commendable job of implementing the basics of OData v4 to alleviate as many workplace constraints as possible, and I’m hearing, guessing, and hoping that they’ll do an equally commendable job of supporting existing namespaces and implementations, but it’s a sunset moment for WCF-DS.
That’s all I have on the subject for now, but feel free to engage me and the community via comments below.
Thanks to the following sites for info and inspiration…
http://en.wikipedia.org/wiki/SOAP
I'm On a Boat
As you read this, I’m in the Pacific ocean, actually hopefully I’m on the Pacific ocean in a sail boat.
If you know me, you know that I’m a little into sailing. It would be more accurate to say that I’m into cruising. Sailing is something you do to make a boat go forward without costing you any money. Cruising is something you do to spend time with friends and family in the sun, in the water, in the wild.
I get precious little time to do either right now since I’m raising a young family, but my wife and I are entertaining eventual dreams of some serious voyaging and decided to get some big ocean experience sooner than later to append to my extensive coastal cruising days.
I’ll be at sea for about 1200 miles without any site of land, and you can bet I brought some serious digital resources to take advantage of the long helm shifts.
So if you send me an email, you’ll get an OOF message. I won’t be checking it out here. There will be no flashing lights (except for my GoPro) or ringing chimes for missed text messages.
If my sanity returns with me I’ll post photos here.
Fair winds.
Git Cheat Sheet
I spend a lot of time using Git these days. It’s one of those technologies you love and hate. I guess I use it because it feels just scrappy and simple and elegant enough to be the right tool for the job in most cases.
I’ve heard it said and completely agree that Git would be the ideal offline source control solution if you didn’t have to search online for the syntax.
Well, maybe this will help. GitHub was at OSCON and they were handing out these handy little cheat sheets. I’m going to decorate my workstation wall with this. Perhaps you’ll save it somewhere close or print and pin it yourself and get some use out of it. Hope so. Cheers.
Acquiring Images Without Committing Plagiarism
The easiest way to find the image you’re looking for is a Bing/Google image search.
Did you know, though, that Bing and Google (and likely the other players) actually do their best to index the licenses associated with the images they crawl?
In a Google Images search, you perform a search and then hit Search Tools and then drop down the Usage Rights. As to why Google gives us astronaut Neapolitan and strawberry waffles… well, I can’t speak to that, but I’m sure those algorithms are really hard to write so we should have grace.
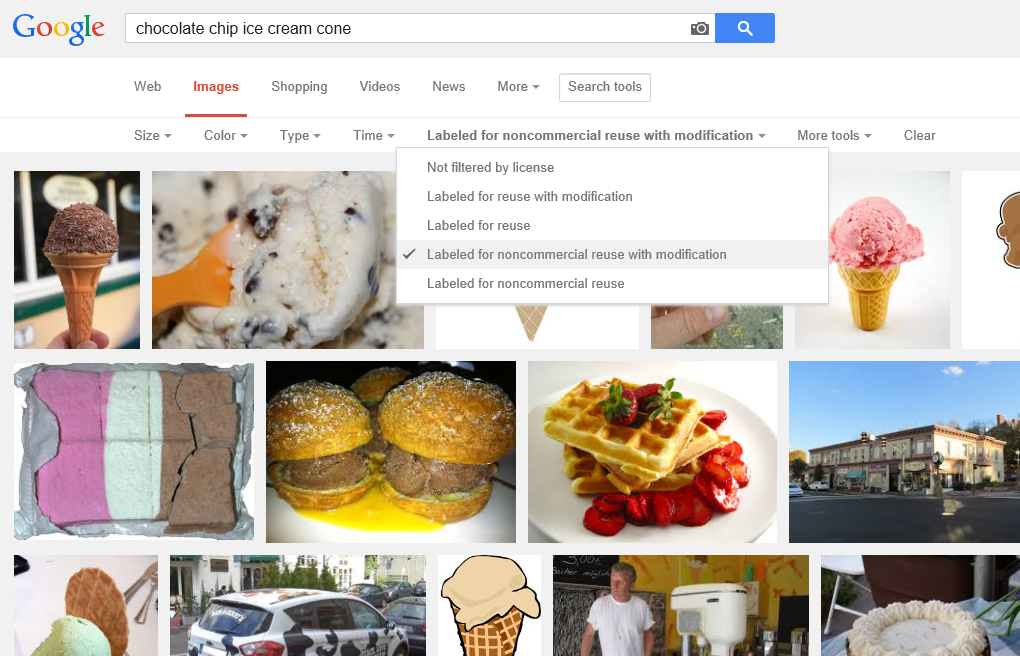
In a Bing Images search, you perform your search and then drop down the License list.
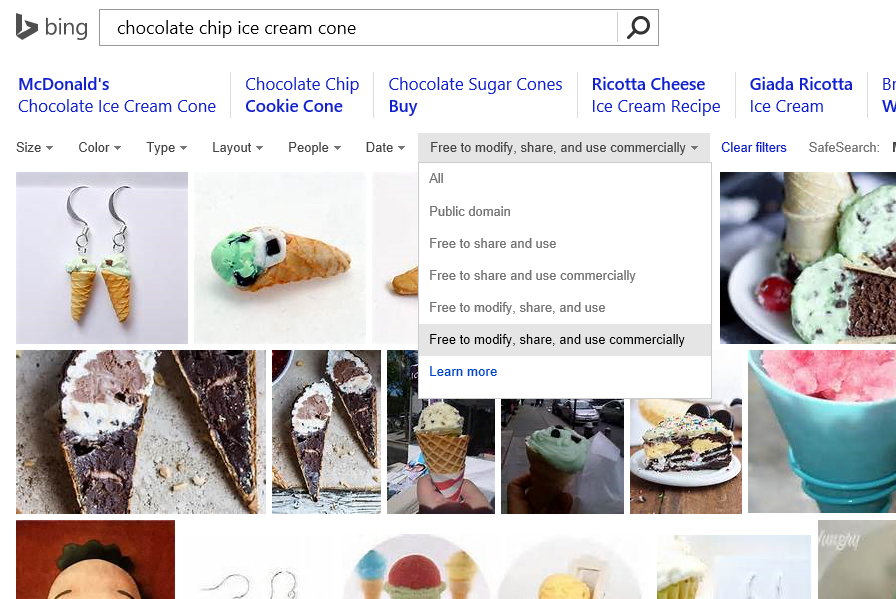
In either case, your search results are going to be severely limited, but you’re going to be able to sleep well at night knowing that you didn’t just rip an image off of someone’s site without a second thought only to reproduce it on your own and in the process breaking the law, ruining your name, and on and on.
I would imagine that this sort of search filter is highly dependent on the presence of some good metadata, so in order to be on the safe side, I still recommend you click through to the site where the image was found and do the leg work to figure out if it’s really in the public domain.