
Posts tagged with "electronics"
Edge Device Discovery - an Unfinished Project
The Team
| Team Member | Project |
|---|---|
| Masha Reutovski | Project Manager |
| Bret Stateham | BLE Communicator |
| Gandhali Samant | BLE Scanner |
| Kristin Ottofy | Sync Engine |
| Joe Raio | API |
| Jeremy Foster | UI |
A diverse group of technical engineers and one project manager from Microsoft’s Commercial Software Engineers (CSE) group. This project was an initiative that Bret Stateham submitted for Sync Week hacks.
Project Overview
This IoT Edge Device Discovery project is built on the Azure IoT Edge service. First, we’ll discuss Edge and then this project’s added value.
Azure IoT Edge
IoT Edge is a service that comes as part of Azure’s IoT offering. It is intended to run on field gateway devices (“edge” devices) and facilitate the aggregation of data from other devices in an on-site IoT solution - devices that may not have the ability to communicate directly with the cloud or for whatever other reason should send their data through a gateway.
Azure’s IoT Edge service is undergoing a big transformation from version 1 to version 2. Version 1 is already in the wild. Version 2 offers some dramatic benefits such as containerized modules that can be run on the edge or in the cloud, but this version is still in private preview and undergoing breaking changes.
In this project, we opted to focus on IoT Edge v1. We are fairly confident that any value added would not be difficult to port to version 2 in case the opportunity arises. We also recognize that IoT Edge v2 may include some functionality that partially or perhaps even entirely overlaps with this project.
IoT Edge v1 offers multiple development paths, including native development in C++, NuGet packages to boot strap .NET development, Maven packages to get started with Java, or npm packages for Node.js developers. We chose to go with the Node.js development path in based on initial research around the noble npm package for access Bluetooth Low Energy (BLE) devices in Node.js.
IoT Edge v1 can be run on a variety of devices and operating systems. For this project, we opted to use the Raspbery Pi 3 running Raspbian Jessie as the gateway device because it was known to be compatible with IoT Edge v1 and had an integrated Bluetooth hardware stack that was known to be compatible with the noble npm package.
Finally, BLE is a popular standard and there are countless devices that could be discovered and communicated with. For this project, we focused on the TI Sensor Tag CC2541 and CC2650 as our reference devices. These sensors have a number of sensors we could leverage and provided a good model for other BLE devices.
IoT Edge Device Discovery
In IoT Edge as it exists today, if a solution administrator needs to pull a new device in to the network to start recording and sending data to the cloud, the process is a bit difficult. The devices that might be added could be speaking various protocols, but for this project we focused on BLE devices.
The current process for bringing new BLE devices into a solution to start getting new data looks something like this…
- new BLE device is brought into the proximity of the solution
- admin manually retrieves the device’s MAC address and characteristics array
- admin adds the MAC address and characteristics to the IoT Edge configuration file
- admin restarts the edge service
This solution would provide a means for these devices to be discovered automatically and simply approved by solution administrators. The process would look more like this…
- new BLE device enters the premises
- Edge service sees the device (including its MAC address and entire characteristics array) and submits it to a cloud service for storage and approval (Edge does not yet begin receiving communication from the device or acting on its reported data)
- admin is notified and directed to a web portal to approve the device and configure the system’s behavior for using the device’s data
- admin either clicks approve or deny for the device
- upon approval, the Edge service begins acting upon data reported from the new device
This system would obviously be extended to support other network protocols besides BLE.
Architecture
In its current state, the solution consists of the following components…
BLE Scanner: the BLE Scanner module is specific to the BLE protocol and would be duplicated for other network protocols. The scanner is just another Edge module and constantly scans for BLE devices in the proximity of the gateway’s BLE radio. Upon seeing a device, the scanner reports the device and its characteristics array (the data points the device is capable of communicating) to the Sync Engine (also an Edge module) using the IoT Edge Message Broker. The Sync Engine is not concerned with whether devices have been discovered and reported in the past or whether they’ve already been approved or denied. It simply reports what it discovers.
Sync Engine: the Sync Engine is also an Edge module and contains the majority of the business logic for this project. It receives information from the BLE Scanner module about what devices have been discovered nearby, their MAC address, and their characteristics array, and it keeps information about these devices synchronized with the data service in the cloud (via the API). It likely receives duplicate devices from the device scanners, but maintains last known state both locally and in the cloud.
BLE Communicator: The BLE Communicator is specific to the BLE protocol and would be duplicated for other network protocols. The communicator is also an Edge module and is responsible for communicating with the entire array of approved BLE devices. This is in contrast to IoT Edge’s default, native BLE module that is delivered with the product, which is only capable of speaking with a single BLE device. The BLE Communicator module maintains configuration on disk as well as in memory and relies on the Sync Engine module to update its configuration and let it know which devices (and which characteristics) it should be communicating with.
API: the Sync Engine runs serverlessly as an Azure Function. It provides endpoints for the Sync Engine and UI. The API allows the Sync Engine module to submit newly discovered devices (and their characteristic arrays) or update existing ones. The API then provides this information to the UI. The API is designed as a REST-compliant interface and thus relies on HTTP GET, POST, PUT, and DELETE operations against entity endpoints - the primary endpoint being the list of devices which may be more clearly understood as device approvals.
UI: the UI is the only interaction point for solution administrators and allows the admin to determine which discovered devices should be considered by the Edge service, which of those devices’ characteristics should be read, which should be written, and on what schedule (i.e. once, periodically, etc.). The UI obviously relies on the API to ultimately take effect in the Edge service.
Components
The Scanner
Principal Developer: Gandhali Samant
Overview
The role BLE Scanner module, as mentioned above, is to discover BLE devices in range of the IoT Edge v1 gateway device. The module was written using Node.js and leverages the noble (https://github.com/sandeepmistry/noble) npm package. Noble supports both Windows and Linux and is the most popular node.js package for BLE communication. This module is intended to constantly scan for new BLE devices and their characteristics. When a new device is discovered the module generates a new message containing the devices MAC address and GATT characteristics and publishes the message to the IoT Edge v1 Message Broker for consumption by other modules.
Challenges
IoT Edge v1 implementation doesn’t support the use of native Node.js modules. The noble npm package is a native npm package (meaning it has to be compiled for the platform) and we were unable to create an IoT Edge module that tried to load the noble package. The solution was to use the proxy, or remote, module patter as discussed here: https://github.com/Azure/iot-edge/blob/master/samples/proxy_sample/README.md . However, that presented it’s own challenge as discovered in #2.
The Node.js implementation of the out of process proxy module is buried in a subfolder of the IoT Edge v1 GitHub repository and can’t be referenced directly from Node.js We attempted to extract that folder only and create a locally linked npm package to depend on, but ultimately ended up having to move that code into our own repo (https://github.com/bretstateham/azipg) so we could create a dependency on it from our IoT Edge v1 module.
The noble BLE implementation was great in that it was able to discover BLE devices, but it turns out there were hundreds of BLE devices available. We added a MAC address filter to discover and report only on BLE devices with MAC Addresses that started with “54:6c:0e”, the prefix used by Texas Instruments CC2650 Sensor Tags to limit the number of devices we published.
Successes
Once the challenges above were overcome, the module was able to successfully scan and discover the two TI CC2650 Sensor tag devices we had on hand. Once discovered, the details of a BLE device were collected, placed in a JSON payload, and published via the IoT Edge v1 Message Broker.
Future Development
The module will currently continue to publish the MAC address of a BLE device even if it has been previously discovered and approved or rejected. It would ideal for it to be able to use a local data store to identify only new BLE devices that need to be reported.
The Sync Engine
Principal Developer: Kristin Ottofy
Overview
The Sync Engine IoT Edge module awaits to receive a message from the Scanner module that a new BLE device has been discovered. It then checks a local file to determine if the device has been approved or not. If the device is not listed in the file, then the Sync Engine calls the get-approval API to alert the user of a new approval request on the UI and adds the device information to the local file. The Sync Engine asynchronously and routinely calls the get-devices API to check if the UI has updated the database. If it has, then the Sync Engine will reflect those changes in the local file to retain state on the gateway device and publish a message on the IoT Edge broker for the BLE Communicator Module to begin communication with the newly approved device. This module was written in Node.js and developed using Raspian Jesse on a Raspberry Pi 2.
Challenges
Many of the challenges with this module were presented during the architecture phase. Retaining state across device power cycles or updates proved to be one challenge. The decision to use a local JSON file to store important information allowed us to get up and running quickly during the hackathon.
Successes
As this portion of the project is continuing development, successes have been made so far with communicating across the gateway message broker, storing information into the local file, making necessary API calls, and posting messages to the broker through various npm packages.
Future Development
There are opportunities available within the gateway device that could support the Sync Engine module through IoT Edge v2. Having a localized database would eliminate the need for the local file and allow for quicker checking of approved devices.
The BLE Communicator Module
Principal Developer: Bret Stateham
Overview
The BLE Communicators role is to implement the actual communication with the approved BLE devices. A single instance of the module is used to communicate with ALL of the configured BLE devices as opposed to a single module instance per device. In addition to multiple devices, the module needed to support multiple communication patterns with the GATT characteristics on any given BLE device. The actual GATT characteristics and their usage pattern is be supplied to the BLE module via the IoT Edge v1. configuration mechanism:
Read Once at Init: A characteristic that is read once at the beginning of communication with the device. The GATT Characteristic value would be read, and included in a message sent to the IoT Edge v1 Message Broker. Read Once values typically include device metadata like Manufacturer, Firmware version, Serial Number, etc.
Write Once at Init: A characteristic that would be written to once at the beginning of communication with the device. The value to be written would come from the module configuration. This is often used to initialize the BLE device itself by enabling sensors, notifications, etc.
Write Once at Exit: A characteristic that would be written to once at the end of communication with the device. The value to be written would come from the module configuration. This is often used to turn off sensors, or features on the device to help reduce it’s power consumption when not in use.
Read Periodic: A characteristic that is read at a regular interval (the interval specified in the config). All periodic read sensor values would be collected and published to the Message Broker in a single payload.
Read Notification: A characteristic on the BLE device that supports notifications. The characteristic’s value will be published individually to the IoT Edge v1 Message Broker.
Challenges
This module shares the same core development foundation as the BLE Scanner above, and as such the same challenges around IoT Edge v1’s limitation around native npm packages. See the BLE Scanner challenges above for more details.
In addition to those challenges, we had some concurrency issues in the Node.js code that we were unable to resolve during the timeframe of the hackfest. The noble implementation is naturally asynchronous, but we were having issues maintaining the context of a characteristic read once the value was returned. We attempted numerous patterns include the use of promises, and the “async” module, but were unsuccessful.
Successes
We were able to get the module to read it’s configuration via the IoT Edge v1 configuration mechanism and initiate communication with the specified BLE devices.
Future Development
The code for this module needs to be refactored to properly leverage the asynchronous behavior of the noble module. In addition, the implementation of the various usage patterns above need to completed.
The API
Principal Developer: Joe Raio
Overview
We exposed four Azure Functions as our API for device management. This would be accessed by the front end to list all devices, get details on a specific device, create a new device, and update the properties of a device. All functions were written in node.js and setup and triggered via HTTP.
API Development, Debugging & Testing
We developed the functions locally using both the Azure Functions Core Tools and VS Code. This allowed us to rapidly iterate through changes as well as debug our code. This saved us a tremendous amount of time vs having to deploy to Azure each time we needed to verify our code updates.
Postman was used to both test API calls locally and against the live site. This allowed us to modify our request body on the fly and send GET, POST, and PUT requests to the API.
Challenges
Proxy Routes using /api – We set out with a goal of being able to call /api/device using different methods (i.e. POST, PUT, GET) which would in turn route to different Azure Functions. To do this we had to enable the use of Function Proxies. When doing this though it would not allow us to use /api in the route prefix because /api is the default route when creating a new function. To overcome this we modified the host.json and changed the default route for functions to /func. This allowed us to then use /api/device with our proxies.
MongoDB API – It was decided that that MongoDB API would be used to interact with CosmosDB. Because of this we were unable to use the built in CosmosDB bindings for Azure Functions. We had to use the Mongo npm packages and write custom code to read / write / update records in the database. While this was not a huge hurdle it would have been cleaner (and faster) for us to use the default DocumentDB api. Future version of the API will use this.
CORS – Early on we ran into CORS issues when trying to access the API from our front-end application. We found that when using proxies our default CORS rules were overwritten. We got past this by adding custom headers to each function directly in the code. Further testing needs to be done to determine the exact cause of this issue.
The UI
Principal Developer: Jeremy Foster
Overview
One part of the overall project workflow required a user interface – the authentication of found devices. For this, we turned to Angular and got a bit creative and modern in how we hosted this application – serverlessly!
Angular
Angular’s CLI makes getting started with a new website pretty quick and easy. Angular is a good, modern choice for a UI and offers plenty of features for this application.
Using the CLI, we had a basic site in just a couple of minutes. Then we added a simple DeviceList component and displayed this component on the main page… nothing fancy… one component.
The most interesting part of the UI was the DataService, which is responsible for fetching devices from the API, displaying them in the UI through the device list component, and keeping the list up to date as new devices are discovered and administrators approve or deny devices.
The next step in this part of the project would be to create another Angular component – perhaps called Device – that the DeviceList component would repeat. That Device component would then contain all of the UI and logic for user interactions for managing the devices – for instance, an Approve button and an Always Ignore button.
Next, because we started with BLE devices for this project, the individual found devices would need to have their characteristics (the properties on each device we’re able to read/write data values from/to) enumerated and give the administrator the ability to determine which characteristics are interesting and how those characteristics should be read (i.e. once, periodically, etc.).
REST Architecture
The API was designed to follow a pure REST architecture, so the higher level operations were absorbed by the UI’s DataService. In the future, a data access layer of sorts could be implemented in a separate or the same API project to make calling from our UI or other UI formats simpler and more consistent.
As an example, in order to keep the API pure REST, a call to approve a device would be something like…
PUT /api/device { "id":14, "approved":false } |
In the UI’s DataService, however, that would simply be a call to a higher level function like this…
approveDevice(14); |
Serverless Hosting
Being the UI is composed of all static files, we could serve it as a Serverless website by using an Azure Function with a custom proxy.
To do this we first created an empty blob container. In this container, we placed the production output of the Angular App (i.e. the /dist folder). Then, using a custom proxy route we routed all requests for /{restofpath} to the public url for the container.
The route definition is as follows:
"root": { |
With %mycontainer_uri% being an app setting for the URI for the blob storage account.
By doing this we avoid having a web app using 24/7 just to serve up static files. When a request is made, the Azure function simply pulls the file from blob storage and serves it to the browser.
You can view the live site here: https://edgediscover-functionapp.azurewebsites.net/index.html
To deploy the UI we used VSTS to create a custom build process with the following steps:
Get Sources – This gets the latest files that were committed to the repo
npm Install – installs all the required npm packages
npm run build-prod – this produces the output of the UI in the /dist folder
AzCopy – this then takes the output and copies it to the specified blob container.
Conclusion
Like many good projects, this one is unfinished, but I hope you have learned like I have to embrace unfinished projects. If you have to bring everything to completion, you may not start some things even though there may be a lot to learn. I certainly learned a lot on this one.
The Most Basic Way to Access GPIO on a Raspberry Pi
I’ve been hacking on the Raspberry Pi of late and wanted to share out some of the more interesting learnings.
I think people that love technology love understanding how things work. When I was a kid I took apart the family phone because I was compelled to see what was inside that made it tick. My brother didn’t care. If it made phone calls, he was fine with it. I had to understand.
Likewise, I knew that I could use a Node library and change the GPIO pin levels on my Raspberry Pi, but I wanted to understand how that worked.
In case you’re not familiar, GPIO stands for General Purpose Input/Output and is the feature of modern IoT boards that allows us to controls things like lights and read data from sensors. It’s a bank of pins that you can raise high (usually to something like 3.3V) or low (0V) to cause some electronic behavior to occur.
On an Intel Edison (another awesome IoT board), the platform developers decided to provide a C library with mappings to Node and Python. On the default Edison image, they provided a global node module that a developer could include in his project to access pins. The module, by the way, is called libmraa.
On a Raspberry Pi, it works differently. Instead of a code library, a Pi running Raspbian uses the Linux file system.
When you’re sitting at the terminal of your pi (either hooked up to a monitor and keyboard or ssh’ed in), try…
cd /sys/class/gpio |
You’ll be taken to the base of the file system that they chose to give us for accessing GPIO.
The first thing to note is that this area is restricted to the root user. Bummer? Not quite. There’s a way around it.
The system has a function called exporting and unexporting. Yes, I know that unexport is not a real word, but alas I’m not the one that made this stuff up, and besides, who said Linux commands had to make sense?
To access a pin, you have to first export that pin. To later disallow access to that pin, you unexport it.
I had a hard time finding good documentation on this, but then I stumbled upon this znix.com page that describes it quite well. By the way, this page references “the kernel documentation,” but when I hit that link here’s what I get…

Oh well.
Now keep in mind that to follow these instructions you have to be root. You cannot simply sudo these commands. There is an alternative called gpio-admin that I’ll talk about in a second. If you want to just become root to do it this way, you do…
su root |
If you get an error when you do that, you may need to first set a password for root using sudo passwd.
To export then, you do this…
echo <pin number> > /sys/class/gpio/export |
And the pin number is the pin name - not the header number. So pin GPIO4 is on pin 7 on an RP2, and to export this you use the number 4.
When you do that, a virtual directory is created inside of /sys/class/gpio called gpio4, and that directory contains virtual files such as direction, value, edge, and active_low. These files don’t act like normal files, by the way. When you change the text inside one of these files, it actually does something - like perhaps the voltage level on a GPIO pin changes. Likewise, if a hardware sensor causes the voltage level on a pin to change, the content of one of these virtual files is going to change. So this becomes the means by which we communicate in both directions with our GPIO pins.
The easiest way, then, to read the value of the /sys/class/gpio/gpio4/value file is…
cat /sys/class/gpio/gpio4/value |
Easy.
To write to the same file, you have to first make sure that it’s an out pin. That is, you have to make sure the pin is configured as an output pin. To do that, you change the virtual direction file. Like this…
echo out > /sys/class/gpio/gpio17/direction |
That’s a fancy (and quick) way to edit the contents of the file to have a new value of “out”. You could just use vi or nano to edit the file, but using echo and the direction operator (>) is quicker.
Once you have configured your pin as an output, you can change the value using…
echo 0 > /sys/class/gpio/gpio4/value //set the pin low (0V) |
Now that I’ve described the setting of the direction and the value, you should know that there’s a shortcut for doing both of those in one motion…
echo high > /sys/class/gpio/gpio4/direction |
There’s more you can do including edge control and logic inversion, but I’m going to keep this post simple and let you read about that on the znix.com page.
Now, although it’s fun and satisfying to understand how this is implemented, and it might be fun to manipulate the pins using this method, you’ll most likely want to use a language library to control your pins in your app. Just know that the Python and Node libraries that change value are actually just wrappers around these file system calls.
For instance, let’s take a look at the pi-gpio.js file in the pi-gpio module…
write: function(pinNumber, value, callback) { |
When you call the write() method in this library, it’s just calling the file system.
So there you have it. I hope you feel a little smarter.
Easy and Offline Connection to your Raspberry Pi
Getting a Raspberry Pi online is really easy if you have an HDMI monitor, keyboard, and mouse.
Subsequently getting an SSH connection to your pi is easy if you have a home router with internet access that you’re both (your PC and your pi) connected to.
But let’s say you’re on an airplane and you pull your Raspberry Pi out of its box and you want to get set up. We call that provisioning. How would you do that?
I’ll propose my method.
First, you need to plug your pi into your PC using an ethernet cable. If you’re a technologist of old like I am, you may be rummaging through your stash for a crossover cable at this point. It turns out that’s not necessary though. I was pretty interested to discover that modern networking hardware has auto-detection that is able to determine that you have a network adapter plugged directly into another network adapter and crosses it over for you. This means I only have to carry one ethernet cable in my go bag. Nice.
If you put a new OS image on your pi and boot it up, it already detects and supports the ethernet NIC, so it should get connected and get an IP automatically.
Here comes the seemingly difficult part. How do you determine what the IP address of your pi is if you don’t have a screen?
The great thing is that the pi will tell you if you know how to listen.
The means by which you listen is called mDNS. mDNS (Multicast DNS) resolves host names to IP addresses within small networks that do not have a local name server. You may also hear mDNS called zero configuration and Apple implemented it and felt compelled (as they tend to) to rename it - they call it Bonjour.
This service is included by default on the Raspberry Pi’s base build of Raspbian, and what it means is that out of the box, the pi is broadcasting its IP address.
To access it, however, you also need mDNS installed on your system. The easiest way I am aware of to do this is to download and install Apple’s Bonjour Print Services for Windows. I’m not certain, but I believe if you have a Mac this service is already there.
Once you have mDNS capability, you simply…
ping raspberrypi.local -4 |
The name raspberrypi is there because that’s the default hostname of a Raspberry Pi. I like to change the hostname of my devices so I can distinguish one from another, but out of the box, your pi will be called raspberrypi. The .local is there because that’s the way mDNS works. And finally, the -4 is an argument that specifically requests the IPv4 address.
If everything works as expected you’ll see something like…
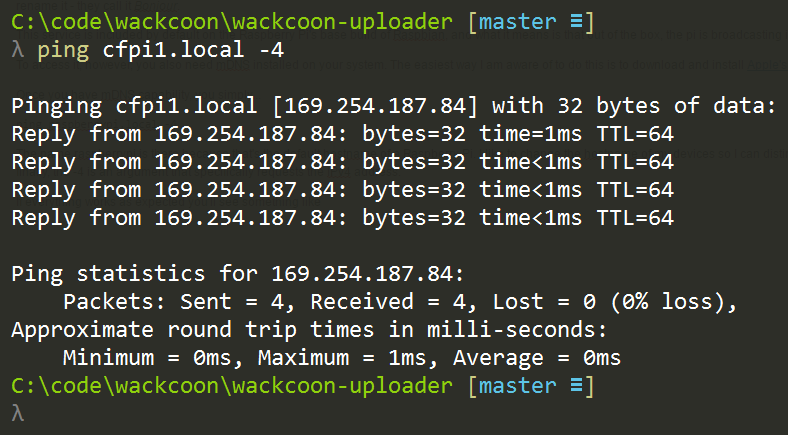
Again, my pi has been renamed to cfpi1, but yours should be called raspberrypi if it’s new.
My system uses 192.168.1.X addresses for my wireless adapter and 169.254.X.X for my ethernet adapter.
So that’s the information I needed. I can now SSH to the device using…
ssh pi@169.254.187.84 |
I could just use ssh pi@raspberrypi.local to remote to it, but I’ve found that continuing to force this local name resolution comes with a little time cost, so it’s sometimes significantly faster to hit the IP address directly. I only use the mDNS to discover the IP and then I use the IP after that.
Provisioning a Raspberry Pi usually includes a number of system configuration steps too. You need to connect it to wireless, set the locale and keyboard language, and maybe turn on services like the camera. If you’re used to doing this through the Raspbian Configuration in XWindows, fear not. You can also do this from the command line using…
sudo raspi-configuration |
Most everything you need is in there.
You may also be wanting to tell your pi about your wifi router so it’s able to connect to via wireless the next time you boot up. For that, check out my post at codefoster.com/pi-wifi. Actually, if you’re playing a lot with the Raspberry Pi, you might want to visit codefoster.com/pi and see all of the posts I’ve written on the device.
Happy hacking!
Accidental Old Version of Node on the Raspberry Pi
I beat my head against a wall for a long time wondering why I wasn’t able to do basic GPIO on a Raspberry Pi using Node. Even after a fresh image and install, I was getting cryptic node error messages when I ran my basic blinky app.
Lucky for me (and perhaps you) I got to the bottom of it and am going to document it here for posterity. Let’s go.
The head beating happened at a hackathon I recently attended with some colleagues.
The task was simple - turn on an LED. It’s so simple that it’s become the “hello world” app of the IoT world. There’s zero reason in the world why this task should take more than 10 minutes. And yet I was stumped.
After a fresh image of Raspbian, an install of NVM, and then a subsequent installation of Node.js 6.2.2, I wrote a blink app using a variety of modules. I used pi-gpio, rpi-gpio, onoff, and finally johnny-five and the raspi-io driver.
None of these strategies were successful. Ugh. Node worked fine, but any of the libraries that accessed the GPIO were failing.
I was getting an obscure error about an undefined symbol: node_module_register. No amount of searching was bringing me any help until I found this GitHub issue where nodesocket (thanks, nodesocket!) mentioned that he had the same issue and it was caused by an NVM install of Node and an accidental, residual version of node still living in /usr/local/bin. In fact, that was exactly what was happening for me. It was a subtle issue. Running node -v returned my v6.2.2. Running which node returned my NVM version. But somewhere in the build process of the GPIO modules, the old version (v0.10) of node from the /usr/local/bin folder was being used.
There are two resolutions to this problem. You can kill the old version of node by deleting the linked file using sudo rm /usr/local/bin/node and then create a new one pointing to your NVM node. I decided, however, to deactive NVM…
nvm deactivate |
…and then follow these instructions (from here) to install a single version node…
wget http://nodejs.org/dist/v6.2.2/node-v6.2.2-linux-armv7l.tar.xz`` # Copied link |
I like using NVM on my dev machine, but it’s logical and simpler to use a single, static version of Node on the pi itself.
EDIT (2016-12-14): Since writing this, I discovered the awesomeness of nvs. Check it out for yourself.
And that did it. I had blinky working in under 3 minutes and considering I get quite obsessive about unresolved issues like this, I had a massive weight lifted.
BTW, through this process I also learned about how the GPIO works at the lowest level on the pi, and I blogged about that at codefoster.com/pi-basicgpio.
Wifi on the Command Line on a Raspberry Pi
I hate hooking a monitor up to my Raspberry Pi. It feels wrong. It feels like I should be able to do everything from the command line, and the fact is I can.
If you’re pulling your Raspberry Pi out of the box and are interested in bootstrapping without a monitor, check out my other post on Easy and Offline Connection to your Raspberry Pi.
Afterward, you may want to set up your wifi access - that is, you want to tell your pi about the wireless access points at your home, your coffee shop, or whatever.
Doing that from the command line is pretty easy, so this will be short.
You’re going to be using a utility on Raspbian called wpa_cli. This handles wireless configuration and writes its configuration into /etc/wpa_supplicant/wpa_supplicant.conf. You could even just edit that file directly, but now we’re talking crazy talk. Actually, I do that sometimes, but whatever.
First, run…
wpa_cli status |
…to see what the current status is. If you get Failed to connect to non-global ctrl_ifname: (null) error: No such file or directory, that’s just a ridiculously cryptic error message that means you don’t have a wifi dongle. Why they couldn’t just say “you don’t have a wifi dongle” I don’t know, but whatever.
If you do have a wifi dongle, you’ll instead see something like…
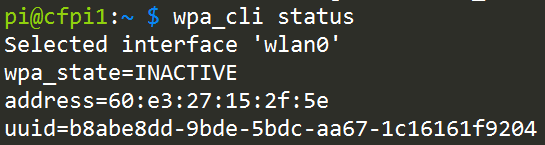
Yay! You have a wireless adapter, which means you likely have a wifi dongle plugged into a USB port. It says here that the current state is INACTIVE. That’s because you’re not connected to any access points.
To do so, you need to run scan, but at this point, you may want to enter the wpa_cli interactive mode. That means that you don’t have to keep prefixing your commands with wpa_cli, but can instead just type the commands. To enter interactive mode, just do…
wpa_cli |
To get out at any time just type quit <enter>.
Now do a scan using…
scan |
It’s funny, because it appears that nothing happened, but it did. Use…
scan_results |
…to see what it found.
This scanning step is not necessary, by the way, there’s a good chance you already know the name (SSID) of your access point, and in that case you don’t need to do this.
Next you create a new network using…
add_network |
You’ll get an integer in return. If it’s your first network, you’ll get a 0. That’s the ID of the new network you just created, and you’ll use it on these subsequent commands.
To configure your network do this…
set_network 0 ssid "mynetwork" |
Something I read online said that as soon as you enter this, it would start connecting, but I had to also do this to get it to connect…
select_network 0 |
Now there’s one more thing. If you’re like me, you don’t just connect to a single AP. I connect from home, my mifi, my local coffee shop, from work, etc. I want my pi to be able to connect from any and all of those networks.
Adding more networks is as easy as following the instructions above multiple times, but you want to set one more network property - the priority. The priority property takes an integer value and higher numbers are higher priority. That means that if I have network1 (priority 1) and network2 (priority 2), and when my pi boots it sees both of those networks, it’s going to choose to connect to network2 first because it has the higher priority.
Okay, that does it.
If you want to see everything I’ve written about the Raspberry Pi, check out codefoster.com/pi
Index of my Raspberry Pi Posts
I’ve been doing a lot of hacking on the Raspberry Pi, and I’ve written a few articles on the topic. I’ve assembled all of my posts here for easy access.
- Accidental Old Version of Node on the Raspberry Pi - I beat my head against a wall for a long time wondering why I wasn’t able to do basic GPIO on a Raspberry Pi using Node. Even after a fresh image and install, I was getting cryptic node error messages when I ran my basic blinky app.Lucky for me (and perhaps you) I got to the bottom of it and am going to document it here for posterity.
- The Most Basic Way to Access GPIO on a Raspberry Pi - I’m always looking for the lowest level understanding, because I hate not knowing how things work. On a Raspberry Pi, I’m able to write a Node app that changes GPIO, but how does that work? Turns out it’s pretty interesting. I’ll show you.
- Easy and Offline Connection to your Raspberry Pi - Getting a Raspberry Pi online is really easy if you have an HDMI monitor, keyboard, and mouse, but what about if you want to get connected to your Pi while you’re, say, flying on a plane?
- Wifi on the Command Line on a Raspberry Pi - How to configure wireless connections on your Raspberry Pi from the command line.