
Azure Options for Stream Processing
Overview
If you’re not already familiar with the concept of data streaming and the resources available in Azure on the topic, then please visit my article Data Streaming at Scale in Azure and review that first.
In short, data streaming is the movement of datagrams (events and messages) as a component of a software solution, and Azure offers Storage Queues, Service Bus Queues, Service Bus Topics, Event Hubs, and Event Grid as complementary components of a robust solution.
Data streaming is a pipeline, and very generally a pipeline looks like this…

Data comes into our solution, we perform operations to it, and then it reaches some terminal state - storage, a BI dashboard, or whatever.
More specifically, however, in many enterprise scenarios that pipeline looks more like this…

Ingestion
Ingestion is simply getting data into the system. This is, often times, moving bits from the edge (your location) to the cloud.
A natural fit for the ingestion step is Event Hubs. It’s excellent at that. Depending on the nature of the datagrams, however, you could use Service Bus Queues or Topics. You could use Storage Queues. You could even just use a Function with an HTTP trigger or a traditional web service if HTTP works in your case. There are a lot of ways to get data into the cloud, but there are only so many protocols.
Transformation
Transformation is merely changing the data shape to conform to the needs of the solution. It’s extremely common since systems that originate data tend to be as verbose as possible to make sure all information is captured.
One of the first tools a pipeline might employ is Azure Stream Analytics (ASA). ASA is good at transforming data and performing limited analysis. Stream Analytics projects one stream into another that is filtered, averaged, grouped, windowed, or more and it outputs the resulting stream one or more times.
ASA is very good at streams, but you still have to think about whether or not it’s the right job for data transformation. Often times, pumping data streams through a Function does the job, meets your solution’s performance requirements, and may make for a more friendly development environment and an easier management and operations story.
Analysis, Insights, and Actions
Now I’m going to lump the remaining three into one category. They’re often (I’m generalizing) solved with processing of some kind.
Analysis is simply Study the data in various ways, insights are figuring out what the data means to future business, and then actions are the concrete steps we take to steer the business (guided by the insights) to effect positive change.
These steps require either some kind of managed integration (like Logic Apps or Flow) or a custom point of compute that gets triggered every time a datagram is picked up.
This custom point of compute could be your own process hosted either on a virtual machine or in a container or it could be an Azure Function.
The bulk of data analysis in years past has been retrospective - data is recorded and some weeks, months, or even years later, data scientists get a chance to look at it in creative ways to see what they can learn. That’s not good enough for modern business, which moves faster and demands more. We need to do analysis on the fly.
Functions
An Azure Function is simply a function written in your language of choice, deployed to the cloud, possibly wired up to a variety of standard inputs and outputs, and triggered somehow so that the function runs when it’s supposed to.
Any given Function might be a serial component of your data pipeline so that every datagram that comes through passes through it. Or it might be a parallel branch that fires without affecting your main pipeline.
Statelessness
Functions are stateless.
Imagine meeting with a person that has no memory, and then meeting with them again the next day. You’d have to bring with you to that meeting absolutely all of the context of whatever you were working on - including introductions!
If you were in the habit of meeting with people like that, you would be wise to make a practice of agreeing with them of a storage location where you could record everything you worked on. Then you would have to actually bring all of the paperwork with you each time.
Functions are like that. Each time you call them it’s a fresh call.
If you write a Function that doesn’t need any state - say to add a timestamp to any message it receives - then you’re as good as done. If you do need state, however, you have a couple of options.
State
(storage)
(durable functions)
(durable entities)
Scaling Strategy
The whole point of Functions is scale, so you’d better get a deep understanding of Functions’ behavior when it comes to scaling. The Azure Functions scale and hosting article on Microsoft docs is an excellent resource.
If you’re using a trigger to integrate with one of the data streaming services we’re talking about, you’re using a non-HTTP trigger, so pay attention to the note under Understanding scaling behaviors. In that case, new instances are allocated at most every 30 seconds.
If you’re expecting your application to start out with a huge ingress of messages and require a dozen instances right off the bat, keep in mind that it won’t actually reach that scale level for 6 minutes (12 x 30s).
Triggers
Most of the work of wiring your data stream up to Functions happens in the trigger. The trigger is the code that determines just how Functions gets new messages. It contains a few configuration options that attempt to fine tune that behavior, but at the end of the day if that behavior is not what you want, you’ll have to rely on another trigger, since custom triggers are not supported.
You might trigger your Function with a clock so that it fires every 15 minutes, or you might trigger it whenever a database record is created, or as in the topic at hand, whenever a datagram is created in your messaging pipeline.
Let’s focus in here on Functions that are reacting to our data streaming services: Storage Queues, Service Bus Queues, Service Bus Topics, and Event Hubs.
Storage Queue Trigger
The Storage Queue Trigger is as simple as they come. You just wire it up to your Storage Queue by giving it your Queue’s name and connection string. The trigger gives you a few metadata properties, though, that you can use to inspect incoming messages. Here they are…
QueueTriggergives you the payload of the message (if it’s a string)DequeueCounttells you how many times a message has been pulled out of the queue andExpirationTimetells you when the message expiresIdthat gives you a unique message ID.InsertionTimetells you exactly when the message made it into the queueNextVisibleTimeis the next time the message will be visiblePopReceiptgives you the message’s “pop receipt” (a pop receipt is like a handle on a message so you can pop it later)
There are certain behaviors baked into all Function triggers. You have to study your trigger before you use it, so you know how it’s going to behave correctly and if you can configure it otherwise.
One of the behaviors of the Queue trigger is retrying. If your Function pulls a message off of the queue and fails for some reason, it keeps trying up to 5 tries total. After that, it adds a new message to the queue with with “poison” appended to the name, so you can log it or use some other logic. Messages are retried with what’s called an exponential back-off. That means the first time it retries a failed message it might wait 10 seconds, the next time it waits 30, then 1 minute, then 10. I don’t know what the actual values are, but that’s the idea.
The Queue trigger also has some particular behavior with regard to batching and concurrency. If the trigger finds a few messages in the queue, it will grab them all in a batch and then use multiple Function instances to process them. It’s very important to understand what the trigger is doing here, because there’s a decent chance your solution will benefit from some optimization. You can configure things like the batch size and threshold in the trigger configuration (in the host.json).
The same Queue trigger can also be configured as an output binding in Functions so you can write queue messages as a result of your Function code.
I covered the Storage Queue trigger here in pretty good detail, but the remaining will have a lot in common conceptually.
Service Bus Trigger
The Service Bus Trigger takes care of triggering a Function when a new message lands in your Service Bus Queue or Topic. There are plenty of nuances that we’ve uncovered in this trigger, though, so it’s worth spending some time looking at the trigger’s behavior in various configurations.
Take a look at the metadata properties that you get inside a Function that’s been triggered by the Service Bus Trigger…
- DeliveryCount
- DeadLetterSource
- ExpiresAtUtc
- EnqueuedTimeUtc
- MessageId
- ContentType
- ReplyTo
- SequenceNumber
- To
- Label
- CorrelationId
You can read about all of those properties in the docs, but I’ll highlight a couple.
(highlight a couple)
(session enabled queues and subscriptions including the not-necessarily-intuitive scaling behavior around it)
(reference this)
Event Hub Trigger
(properties)
(differentiate from service bus behavior)
Custom Process
(containers)
(reactive-x)
Measuring Latency
link to the other blog post about measuring latency
Data Streaming at Scale in Azure
Overview
Many modern enterprise applications start with data generated by real world events like human interactions or regular sensor readings, and it’s often the modern developer’s job to design a system that will capture that data, move it quickly through some data pipeline, and then turn it into real insights that help the enterprise make decisions to improve business.
I’m going to generalize and call this concept data streaming. I’ll focus on streaming and will not cover things like data persistence or data analysis. I’m talking about the services that facilitate getting and keeping your data moving and performing operations on it while it’s in transit.
Data streaming is an extremely common solution component, and there’s a myriad of software services that exist to fulfill it. In fact, there are so many tools, that it’s often difficult to know where to start. But fear not. The whole point of this article is to introduce you to Azure’s data streaming services.
Datagrams
When you’re streaming data, the payload is up to you. It might be very small like a heartbeat or very large like an entire blob. Often, streaming data is made up of messages or events. In this article, I’ll use the term datagram (lifted from Clemens Vasters’ article) to refer abstractly to any payload whether you would consider it a message or an event.

What exactly is the difference between an event and a message. The official Azure documentation contains an article called Choose between Azure messaging services - Event Grid, Event Hubs, and Service Bus that does a great job with explaining this, so read that first, and then here’s my take.
An event is a bit like a system level notification. You and I get notifications on our mobile devices because we want to know what’s going on, right?
The battery level just dropped to 15%. I want to know that so I can plug it in.
I just got a text message from Terry. I’ve been waiting to hear from her, so that’s significant.
Somebody outbid me on that auction item. I need to consider raising my bid.
I might want events to be raised even if I don’t plan to respond to them right away too, because I might want to go back and study all of those events over time to make sense of them.
A set of events over time looks a bit like a history book, doesn’t it? You could react in real time as events occur, or you could get a list of all of last week’s events and you could essentially replay the entire week. Or you could do both!

The battery level event example I brought up is a pretty simply event, right? Sometimes, however, events are more complicated and domain-specific, like “Your battery level is 5% less than your average level this time of day.” That kind of event takes some state tracking and data analysis. It’s really helpful though.
This is what I call cascading events. The first-level events are somewhat raw - mostly just sensor readings or low-level events that have fired. The next level is some fusion or aggregation of those events that’s higher level and often times more meaningful to an end user or business user - what we might call domain events. And, of course, events can cascade past 2 levels, and at the last level, it’s common to raise a notification - on a mobile device, a dashboard, or an email inbox.
Messages are different though.
Messages are more self-contained packages that relay some unit of information or a command complete with the details of that command.
I used the analogy of a history book to describe all of last week’s events. I suppose all of last week’s messages would be more like a playbook or a transaction log. Notice that my sample messages are more present tense and directive. That’s fairly typical for messages.

One of the defining characteristics of a message is that there is a coupling between the message producer and the consumer - that is, the producer has some expectation or even reliance on what the consumer will do with it. Clemens rightly states that with events “the coupling is very loose, and removing these consumers doesn’t impact the source application’s functional integrity”. So, I can use that as a test. If I stop subscribing to the produced datagrams, will something break? If so, you’re dealing with messages as opposed to events.
Data Streaming Services in Azure
Let’s start with Azure’s data streaming services.
Storage Queues
Not to be confused with Service Bus Queues, Azure’s Storage Queues are perhaps the most primitive and certainly the oldest queue structure available.
In case you’re not familiar with the core concept of a queue, it would be good to explain that. A queue is a data structure that follows a first-in first-out (FIFO) access pattern - meaning that if you put Thing A, Thing B, and then Thing C in (in that order), and then you ask the queue for its next item, it will give you Thing A - first in… first out.

If you studied computer science and you weren’t sleeping during your Data Structures class, then you already know about queues.
Queues are extremely handy in cloud-first applications where it’s common to use one working process to set aside tasks for one or more other working processes to pick up and fulfill. This decoupling of task production from task consumption is a pinnacle concept in fulfilling the elasticity that cloud applications promise. Simply scaling your consumers up and down with your load allows you to pay exactly what you should and no more.
Storage Queues are not as robust as some of the other data streaming services in Azure, but sometimes they are simply all you need. Also, they’re delightfully inexpensive.
Service Bus Queues
Service Bus Queues are newer and far more robust than Storage Queues. There are some significant advantages including the ability to guarantee message ordering (there are some edge cases where Storage Queues can get messages out of order), role-based access, the use of the AMQP protocol instead of just HTTP, and extensibility.
To study the finer differences between Storage Queues and Service Bus Queues, read Storage queues and Service Bus queues - compared and contrasted.
Service Bus Topics
Queues are the solution when you want one and only one worker to take a message out of the queue and process it. Think about incoming pizza orders where multiple workers are tasked with adding toppings. If one worker puts the anchovies on a pizza then it’s done, and the other workers should leave it alone.
Topics are quite different. Topics are the solution when you have messages that are occurring and one or more parties are interested. Think about a magazine subscription where it’s produced one time, but multiple people want to receive a copy. You often hear this referred to as a “publish/subscribe” pattern or simply “pubsub”. In this case, messages are pushed into a topic and zero to many parties are registered as being interested in that topic. The moment a new messages lands, the interested parties are notified and can do their processing.
When dealing with Service Bus Queues and Topics, you’ll hear some unique semantics. The terms At Most Once, At Least Once, and Exactly Once describe how many times a consumer is guaranteed to see a message and the nuances in how the service handles edge cases such as when it goes down while a message is in processing. Peeking at messages allows you to see what’s in the queue without actually receiving it. Whether consumers are peeking or actually receiving messages, locks are put in place to make sure other consumers leave it alone until it’s done. Finally, deadlettering is supported by Queues and Topics and allows messages to be set aside when, for whatever reason, consumers have been unable to process them.
Event Hubs
Now let’s take another view on processing data and look at events instead of messages.
Event Hub is Azure’s solution for facilitating massive scale event processing. It’s ability to get data into Azure is staggering. The feature page states “millions of events per second”.
My understanding as to the differences between Service Bus and Event Hub has come in waves of understanding. Here’s how I understand it now.
Service Bus (both Queues and Topics) is a bit more of a managed solution. That is, the service is applying some opinion about your solution. Opinions, as you may know, can make a service dramatically easier to implement, but they can also constrain us as solution developers by tying us to specific assumed scenarios.
There are a lot of things that Service Bus does for us that Event Hubs does not attempt to do. It caches datagrams and keeps them for the configured time, but it doesn’t decorate them with any status, remember which have been processed, keep track of how many times a datagram has been accessed (dequeued in Service Bus parlance), lock those that have been looked at by any given consumer, or anything like that. It simply stores datagrams in a buffer and if the time runs out on a datagram in the buffer it drops it.
This puts the onus on an Event Hubs consumer to not only read events, but to figure out which ones have been read already.
This lack of management switches us from a pattern called competing consumer to one called partitioned consumer. With competing consumers, the service has to spend a bit of time making sure the competition is fair and goes well. With partitioned consumers, there’s just a clean rule regarding who gets what. So, if you can assume that there is no competition in your processing then you don’t need all the cumbersome status checking, dequeue counting, locking, etc. That’s why Event Hubs is super fast.


Event Grid
Event Grid is newer than both Service Bus and Event Hubs, and it may not be readily apparent what its unique value offering is.
Start by reading Clemens Vaster’s excellent article Events, Data Points, and Messages - Choosing the right Azure messaging service for your data.
Clemens calls Event Grid “event distribution” as opposed to “event streaming”. I like that.
Event Grid is a managed Azure platform with deep integration into the whole suite of Azure resources that creates a broad distribution of event publishers and subscribers between Azure services and even into non-Azure services.
Event Grid is not as much of a streaming solution as Event Hubs is. It’s highly performant, but it’s not tuned for the throughput you would expect to see in an Event Hubs solution.
It’s also a bit of a hybrid because it’s designed for events, but it has some of the management and features you find in Service Bus like deadlettering and At Least Once delivery.
Stream Analytics
Together Service Bus, Event Hubs, and Event Grid make up the three primary datagram streaming platform services, but not far behind as far as central streaming services is Stream Analytics. Heck, it even has Stream in the name.
Stream Analytics uses SQL query syntax (modified to add certain streaming semantics like windowing) to analyze data as it’s moving.
Think about being tasked with counting the number of red Volkswagon vehicles that pass by some point on the highway. One crude approach would be to ask vehicles to pull over until a large parking lot were full, then perform the analysis, and then let those cars go while bringing new ones in. The obvious impact to traffic is analogous to the performance impact on a digital project - horrendous.
The better way is let the cars go and just count them up as they move unfettered. This is what Stream Analytics attempts to do.
Measuring Latency
There are many points in the streaming process where delays may be introduced such as while…
- processing something in the producer before a message is sent
- composing a message
- getting the message to the streaming service
- getting the message enqueued and ready for pickup
- getting the message to the consumer
- processing the message
Other Mentionable Azure Data Services
There are a few other services in Azure that have more distant relationships to the concept of data streaming.
Data services and the often-nuanced differences between one another get truly dizzying. I have so much respect for a data expert’s ability to simply choose the right product for a given solution.
I have to mention IoT Edge and IoT Hub. In the wise words of Bret Stateham “IoT is a data problem waiting to happen”. IoT Hub has an Event Hub endpoint that allows it to integrate with other data services in Azure.
Data Lake is a great place to pump all of your structured or unstructured data to figure out what you’ll do with it next. A data lake is what you find at the end of a data stream - just like IRL!
Databricks gives you the easiest Apache Spark cluster ever. With it you get a convenient notebook interface so you can collaborate and iterate on your data analysis strategies. Databricks is certainly a streaming solution, so if you’re wondering why I didn’t compare it more directly next Service Bus and Event Hub, it’s simply because it’s a very different beast and frankly I’m not overly familiar with it.
Power BI is a business intelligence platform for visualizing data back to humans so that key decisions can be made. It’s worth a mention because it’s capable of receiving data streams and even updating visuals in near real-time.
When your data has been ingested, stored, analyzed, and trained, you drop it into SQL Data Warehouse - a column store database for big data analysis. Not much streaming at play at this stage of the solution, but it’s worth a mention.
Conclusion
I did not bring the conclusion and closure to this research into streaming that I would have liked, but I wanted to get all of this work published in case it’s helpful.
If this is your debut into the concept of data streaming, then welcome to a rather interesting and fun corner of computer science.
Fetch Azure FTP Credentials from the CLI
This is one of those posts I’m writing for future me (hi, future me!).
If you have an Azure Web App and you want to get its application-level deployment credentials (as opposed to its user-level deployment credentials), you need to run two commands using the Azure CLI:
# to get the FTP endpoint |
The second command will give you the three components you need for your username and password credentials. You use the name and publishingUserName together to make your username - like this ${name}\${publishingUserName} in JavaScript template literal syntax, and you use the publishingPassword as the password.
That’s that!
Semantic Selections and Why They Matter
I’m a big fan of at least two things in life: writing code and being productive. On matters involving both I get downright giddy, and one such matter is semantic selection. VS Code calls them smart selections, but whatever.
Semantic selection is overlooked by a lot of developers, but it’s a crying shame to overlook something so helpful. It’s like what comedian Brian Regan says about getting to the eye doctor.
Semantic selection is a way to select the text of your code using the keyboard. Instead of treating every character the same, however, semantic selection uses insights regarding the symbols and other code constructs to (usually) select what you intended to select with far fewer keystrokes.
I used to rely heavily on this feature provided by ReSharper way back when I used heavy IDEs and all ;)
Some may ask why you would depend on the keyboard for making selections when you could just grab the mouse and drag over your characters from start to finish? Well, it’s my strong opinion that going for the mouse in an IDE is pretty much always a compromise - of your values at least but usually of time as well. That journey from keyboard to mouse and back is like a trans-Pacific flight.
I can’t count the number of times I’ve watched over the shoulder as a developer carefully highlighted an entire line of text using the mouse and then jumped back to the keyboard to hit BACKSPACE. Learning the keyboard shortcut for deleting a line of text (
CTRL+SHIFT+Kin VS Code) can shave minutes off your day.
Without features like semantic selection, however, selecting text using the keyboard alone can be arduous. For a long time, we’ve had SHIFT to make selections and CTRL to jump by word, but it’s still time consuming to get your cursor to the start and then to the end of your intended selection.
To fully convey the value of semantic selection, imagine you’re cursor is just after the last n of the currentPerson symbol in this code…
function getPersonData() { |
Now imagine you want change currentPerson to currentContact. With smart selection in VS Code, you would…
- Tap the left arrow one time to get your cursor into the
currentPersonsymbol (instead of on the trailing comma) - Hit
SHIFT+ALT+RIGHT ARROWto expand the selection
Now, notice what got highlighted - just the “Person” part of currentPerson. Smart selection is smart enough to know how camel case variable names work and just grab that. Now simply typing the word Contact will give you what you wanted.
What if you wanted to replace the entire variable name from currentPerson to say nextContact? For that you would simple hit SHIFT+ALT+RIGHT ARROW one more time to expand the selection by one more step. Now the entire variable is highlighted.
One more time to get the entire function signature.
Once more to get the function call.
Once more to get the entire statement on that line and again to get the whole line (which is quite common).
Once more to get the function body.
Once more to get the entire function.
That’s awesome, right?
Integrate this into your routine and shave minutes instead of yaks.
Happy coding!
Beautiful Cascading Node Config
FYI, this is a repost. I lost this post’s source markdown and just recreated it for posterity.
I just learned something, which instantly makes it a good day.
I’ve been on the lookout for a really good pattern in Node.js projects to allow a user to…
Define configuration variables in a JSON config file (not flat environment variables!)
Allow them to override the configuration variables with command line arguments
Make the command line arguments work like any good, modern CLI with double dash full names (i.e.
--foo bar) or single dash aliases (i.e.-f bar)Let the dev know if their code isn’t working because a certain configuration variable hasn’t been set
Here’s what I have now.
let config = require('./arguments.json'); |
So, the arguments.json file that we bring in is a place we can define arguments permanently so they don’t have to be included on the command line.
Then we pull in a dependency on the command-line-args package. I was delighted to discover that this package works exactly like I expected it too. For each argument, we can give it a long name (i.e. argumentA) and a short name (i.e. a). Finally, I added the required property myself, which I’ll show you in a second.
Next, I coerce these two sources of configuration values using a spread operator. I talked a lot more about spread operators in my Level Up Your JavaScript Game! - Other ES6 Language Features post. The order of these two spread objects is such that it will take the values in my file first, but then override them with command line arguments if they exist.
Finally, I added another little trick that wasn’t built in to the command-line-args package (although I think it should be). I added the ability to make certain arguments required, and if not to throw an error so the user knows exactly why things don’t work.
That’s all!
TypeScript for Documentation
TypeScript is wonderful for a variety of reasons and there’s one I want to hightlight right now.
TypeScript allows a developer or team to sprinkle types in to their codebase. These types make it much easier for your IDE to tell you you’re doing something you don’t intend to do in your logic. That’s excellent.
But the types also document your codebase well.
Here’s a function without types…
function sum(n1, n2) { |
And then with types…
function sum(n1: number,n2: number): number { |
And the obvious advantage is that at a glance, I as a human can see what kinds of variables this function is expecting and what it’s going to give me back.
Additionally, my IDE can inspect these types and give me some information about the expected parameter types without even make the journey to the source code to look…
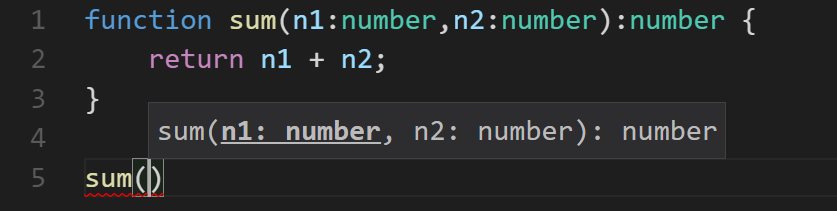
I can take that a step further and add some comments to the source and get even better descriptions.
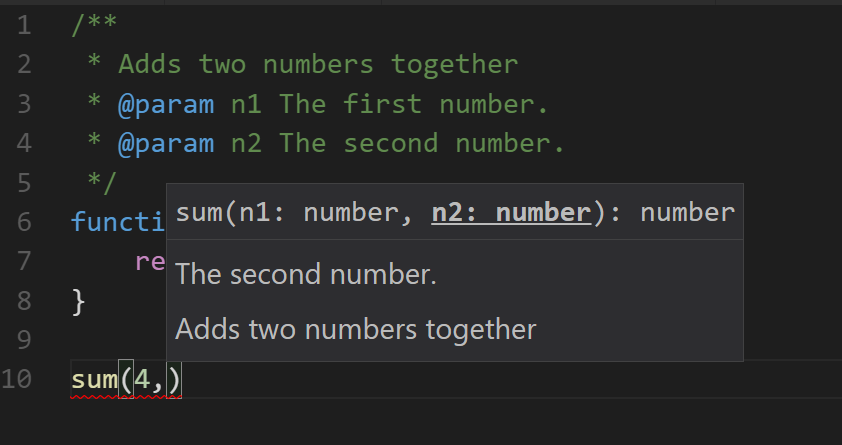
And now I can be more awesome.
A Simple Brain
I’m not (yet) an expert in machine learning, but like so many I recognize that it’s an incredibly integral part of our future.
Right now, most data insights are the result of some significant effort - a lot of data, a lot of training, and perhaps a significant amount of time spent by data scientists.
I anticipate that insights are going to come not only out of these large projects, but out of the small workflows as well. For example, your average web developer may tend to create some marketing information and some web forms online, but in the future, they’ll also apply some machine learning.
I have been dabbling with Brain.js lately, and I wonder if something like this might be a good compliment to some of the massive capability available in very high scale machine learning solutions. Brain.js is just JavaScript, and sometimes that’s all you need - something that will run in small quantity in the browser!
So I copied some code from the Brain.js website and regurgitated it here for your benefit. I also put it into my repo simple-brain.
Here’s the code…
const brain = require('brain.js'); |
I’m learning a lot about ML right now and it’s fun to have a new space to learn and explore. It’s fun too that ML has a bit of a presence in the JavaScript world even though the Python leaning is strong. I found this excellent article by Jonathan who’s as crazy as I am to consider JS for ML at this time.
Zoom in Windows
I do a lot of presentations. The only thing I like more than writing code is talking about writing code.
I’ve always had a little angst about zooming my screen though because…
The built-in Windows Magnifier seemed to get in my way
The excellent and popular Zoom It tool requires an extra install and I never seem to have it running when my presentation starts.
I recently discovered, though, a couple of options that make theh built-in Windows Magnifier work way better for me.
First, I looked up the keyboard shortcuts and beyond the basics of WIN + = for zooming in and WIN + - for zooming out, you can use WIN + ESC to exit the zoom altogether. Prior to discovering that, I thought it was necessary to zoom all the way back out. I also found that CTRL + ALT + Mouse Wheel works to zoom in and out with your mouse.
Now, my biggest aggravation with the Magnifier was how the UI rendered every time I performed a zoom. There’s a Magnifier settings to “Collapse to magnifying glass icon”. That’s better than the full window, but it’s still fairly obtrusive. So here’s the trick.
Start Magnifier so the icon appears on the Task Bar.
Now right click on the Magnifier icon, right click on the Magnifier entry in the context menu, and hit Properties.
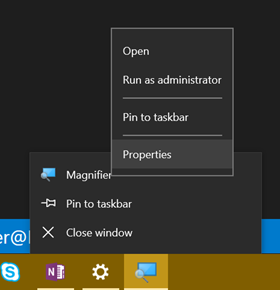
Now set Run to Minimized

That’s it. Now when you hit WIN + = to zoom in, the screen zooms in to the mouse cursor and doesn’t render any obtrusive UI.
It’s the simple things that light me up!
Quick note. A colleague just read and tried this and it didn’t seem to work for him. I tried it again and the behavior is not exactly like I indicated in this post. I spent some time trying to figure out exactly what’s up, and I figured out that if the magnifier is not running, then it will still create the UI. If you check the box I mentioned to earlier - Collapse to magnifying glass icon - the UI is smaller, but it’s still there. The application is not active, but if it happens to show up where your cursor is, then it’s still obstructive. So, I am going to submit this feedback to the Windows team to see if I can be an advocate of change. It does help if you move the Magnifier’s window to a remote area of the screen, and you can also just minimize it, but both of those take a little effort. Anyway, we’ll get this figured out :)
Okay, folks. I submitted this feedback via Windows Feedback and it was promoted to bug 16580796 within the hour. Impressed. Fingers crossed this is fixed in the next Windows update.
Level Up Your JavaScript Game! - Other ES6 Language Features
See Level Up Your JavaScript Game! for related content.
Sometimes it takes a while to learn new language features, because many are semantic improvements that aren’t absolutely necessary to get work done. Learning new features right away though is a great way to get ahead. Putting off learning new features leaves you lagging the crowd and constantly feeling like you’re catching up. I’ve noticed that junior developers often know more modern language features than senior developers.
There are quite a few language features that were introduced in ES5 and ES6, and you’d be well off to learn them all! Certainly, though, look into at least the ones I’m going to talk about here. I recommend you learn…
…to effectively use the object and array spread operators.
From MDN: “Spread syntax allows an iterable such as an array expression or string to be expanded in places where zero or more arguments (for function calls) or elements (for array literals) are expected, or an object expression to be expanded in places where zero or more key-value pairs (for object literals) are expected.”
The spread operator is an ellipsis (
...), but don’t confuse it with the pre-existing rest operator (also an ellipsis). The rest operator is used in the argument list of a function definition. The spread operator on the other hand is used… well, I’ll show you.
Think of the spread operator’s function as breaking the elements of an array (or the properties of an object) out into a comma delimited list. So [1,2,3] becomes 1,2,3. The array spread operator is most helpful for either passing elements to a function call as arguments or constructing a new array. The object spread operator is most helpful for constructing or merging objects properties.
If you have an array of values, you can pass them to a function call as separate arguments like this…
myFunction(...[1,2,3]); |
If you have two objects - A and B - and you want C to be a superset of the properties on A and B you do this…
let C = {...A, ...B}; |
Therefore…
{...{"name":"Sally"},...{"age":10}} |
…to get into the habit of using destructuring where appropriate.
Destructuring looks like magic when you first see it. It’s not just a gimmick, though. It’s quite useful.
Destructuring allows you to assign variables (on the left hand side of the assignment operator (=)) using an object or array pattern. The assignment will use the pattern you provide to extract values out of an object or array and put them where you want them.
let {name,age} = {name:"Sally",age:10}; |
That’s a lot better than the alternative…
let person = {name:"Sally",age:10}; |
It works with nested properties too…
let {name,address.zip:zip} = {name:"Sally",age:10,address:{city:"Seattle",zip:12345}}; |
It works with arrays too…
let [first,,third] = ["apple","orange","banana","kiwi"] |
Destructuring is handy when you’ve fetched an object or array and need to use a subset of it’s properties or elements. If your webservice call returns a huge object, destructuring will help you pull out just the parts you actually care about.
Destructuring is also handy when creating mixins - objects that you wish to sprinkle functionality into by adding certain properties or functions.
Destructuring is also handy when you’re manipulating array elements.
…to use template literals in most of your string compositions.
I recommend you get in the habit of defining string literals with the backtick (`) operator. These strings are called template literals and they do some great things for us.
First, they allow us to line wrap our string literal without using any extra operators. So as opposed to the existing method…
let pet = "{" + |
…we can use…
let pet = `{ |
Elegant!
…to understand the nuances of lambda (=>) functions (aka fat-arrow functions).
And it looks like I’ve saved one of the best for last, because lambdas have so dramatically increased code concision. Not to overstate it, but lambda functions delight me.
I was introduced to lambda functions in C#. I distinctly remember one day in particular asking a fellow developer to explain what they are and when you would use one. I distinctly remember not getting it. Man, I’ve written a lot of lambda functions since then!
The main offering of the lambda is, in my opinion, the concision. Concise code is readible code, grokkable code, maintainable code.
They don’t replace standard functions or class methods, but they mostly replace anonymous functions in case you’re familiar with those. I very rarely use anonymous functions anymore. They’re great for those functions you end up passing around in JavaScript, because… well, JavaScript. You use them in scenarios like passing a callback to an asynchronous function.
Allow me to demonstrate how much more concise a lambda function is.
Here’s a call to that readFile function we were using in an earlier post. This code uses a pattern where functions are explicitly defined before being passed as callbacks. This is the most verbose pattern.
fs.readFile('myfile.txt', readFileCallback); |
Now let’s convert that function an anonymous function to save some lines of code. This is recommended unless of course you’re paid by the line of code.
fs.readFile('myfile.txt', function(contents) { |
Notice that the function name went away. I for one strongly dislike the first pattern. When a callback function is only used once, I feel like it belongs inline with the function call. If of course, you’re reusing a function for a callback then that’s a different story.
Now let’s go big! Or small, rather. Let’s turn our anonymous function into a lambda.
fs.readFile('myfile.txt', txt => { |
I love it! Notice, we were able to do away with the function keyword altogether and we specified it’s argument list (in this case only a single argument) on its own. Notice too that I called that argument txt. I could have, of course, kept the name contents, but I tend to use short (often only a single letter) arguments in lambda functions to amplify the brevity. Lambda functions are very rarely complex, so this works out well.
The loss of the function name and keyword saved some characters, but lambda functions get even shorter. If a lambda contains only a single expression, the curly braces can be dropped. The expression in this case becomes the return value of the lambda.
To illustrate, let me use a new example - this one from my post on arrays in this series…
let numbers = [1,2,3,4,5,6]; |
In this example, n => n <= 3 is a complete lambda function. I know, concise right?! This example illustrates the value of the single letter arguments and also introduces you to the expression syntax. The body of the lambda is n <= 3. That’s an expression. It’s not a statement such as…
let n = 3; |
And it’s not a block of statements such as…
{ |
…and like I said, when the body of your lambda is a simple express, you can drop the curly braces and the expression becomes your return value.
So in the example, the .filter() function wants a function which evaluates to true or false. Our expression n <= 3 does just that, and returns the result.
There are two caveats that I’ll draw out.
First, if you have 1 argument in your lambda function, you do not need parenthesis around the argument list. In our previous example, n => n <= 3 is a good example of that. If you have 0 arguments or more than 1 argument, however, you do. These are all valid…
() => console.log('go!') //0 arguments |
If you use TypeScript, you may notice that the presence of a type on a single argument lambda function requires you to wrap it with parenthesis as well, such as
(x:number) => x * x.
The second caveat is when your lambda returns an expression, but that expression is an object literal wrapped in curly braces ({}). In this case, the compiler confuses your intention to return an object with an intention to create a statement block.
This, then, is not valid…
let generatePerson = (first,last) => {name:`${first} ${last}`} |
To direct the compiler just do what you always did in complex mathematical statements in high school - add some more parenthesis! We could correct this as so…
let generatePerson = (first,last) => ({name:`${first} ${last}`}) |
And there’s one more thing about lambdas that you should know. Lambdas have a feature to remediate a common problem in JavaScript anonymous functions - the dreaded this assignment.
Anonymous functions (and named functions) in JavaScript are Objects, and as such they have a this operator that references them. Lambda functions do not. If you use this in a lambda function, chances are the sun will keep shining and the object you intended to reference will be referenced. No more _this = this or that = this or whatever else you used to use everywhere.
That’ll do it for arrays, and in fact that’ll do it for this series. If you jumped here from a search, headback to Level Up Your JavaScript Game! to see the rest of the content.
Thanks for reading and happy hacking!
Level Up Your JavaScript Game! - ES6 Modules
This post is not yet finished
See Level Up Your JavaScript Game! for related content.
Unfortunately, the whole concept of modules in JavaScript has undergone a ton of evolution and competing standards, and for a while it seems like no two JavaScript environments used modules the same way. Spending a little time figuring out exactly what’s happening goes a long way toward demystifying things.
To level up in JavaScript modules, I recommend you learn…
…to transition from Node.js’s CommonJS modules to ES6 modules.
Node has not yet fully adopted ES6 modules, but it’s coming soon. We developers can today though using a transpiler, and I recommend it. We may as well get into tomorrow’s habits today. Instead of…
const myLib = require('myLib'); |
…use…
import { myLib } from 'myLib'; |
The former strategy - CommonJS - is a well-established habit for most of us, but it’s not inherantly as capable as the latter - ES6 modules. I’m going to assume you’ve used the CommonJS pattern plenty and skip explaining its nuances, and talk only about the newer, better, faster, stronger ES6 modules.
To play with some the concepts on this page, install TypeScript.
npm i -g typescript |
…to define an ES6 module and export all or part of it.
CommonJS modules are defined largely by putting some JavaScript in a separate file and then requiring it. ES6 modules are too. The differences come in how a module describes what it exports - that is what it makes available to anyone who decides to depend on it.
In ES6 modules, you put export on anything you want to export. Period. That’s easy :)
//mymodule.ts |
In the above example, only y would be available to whoever takes a dependency on mymodule.
You can put export on variable declarations (like the let above), classes, functions, interfaces (in TypeScript), and more. Read on to see how these various exports get imported.
…to import an entire module.
To import everything a given module has to offer - all of the exports…
import * as mymodule from './mymodule'; |
The * indicates that we want everything and the as mymodule aliases (or namespaces) everything as mymodule. After this import, we would be free to use mymodule.y in our calling code.
…to import parts of a module.
Let’s say our module looked like this…
//mymodule.ts |
If we decide in our calling code that we need x and we need the sum function, then we can use…
import { x, sum } from './mymodule' |
Notice that we don’t need to prefix the x and sum functions. They’re in our namespace.
…to alias modules on import.
Sometimes, you want to change the name of something you import - for instance, to avoid a naming conflict…
import { x, sum as add } from './mymodule' |
That’ll do it for ES6 module imports. Now head back to Level Up Your JavaScript Game! or move on to my final topic on ES6 features.